动手写个玩具编译器
文章目录
一直对源码如何变成可在电脑上运行的二进制文件很感兴趣,虽然在大学时学过编译原理相关课程,但当时就是为了应对考试,基本了解个大概基本什么都没剩下。这个长假终于有时间作了些研究,终于算是补齐了这块知识盲区。
想弄明白源码到底是如何变成二进制文件的,最好的方式莫过于动手写一个编译器试试。第一知觉,写个编译器应该很难吧。但在现在已经是2020年,各种工具文档满天飞,写个玩具编译器还真不是很难的事。
编译器理论知识
一个编译器是由一组有三个到四个组件(还有一些子组件)构成,数据以管道的方式从一个组件输入并流向下一个组件。在我们这个编译器中,可能会用到一些稍微不同的工具。下面这个图展示了我们构造一个编译器的步骤,和每个步骤中将使用的工具。

上图中Linking这一步一般不需要我们做什么。在文法分析阶段,这里使用开源工具Lex,即如今的Flex,文法分析一般都伴随者语法分析,这里使用的语法分析工具将会是Yacc,或者说是Bison,最后一旦语义分析完成,我们将遍历我们的抽象语法树,并生成”bytecode 字节码”。做这一步,这里使用LLVM,它能生成快速LLVM IR。再使用LLVM自带的工具llc将LLVM IR字节码文件编译为汇编代码文件,最后使用clang++工具将汇编代码文件编译为二进制文件。
总结一下,步骤如下:
- 文法分析用
Flex:将数据分隔成一个个的标记token (标示符identifiers,关键字keywords,数字numbers, 中括号brackets, 大括号braces, 等等etc.) - 语法分析用
Bison: 在分析标记的时候生成抽象语法树. Bison 将会做掉几乎所有的这些工作, 这里只需要定义好抽象语法树就OK了。 - 组装用
LLVM: 这里我们将遍历我们的抽象语法树,并未每一个节点生成字节/机器码。 - 最后用几个命令完成编译为二进制文件的工作。
定义要创造的语法
编译器的输入是源代码,既然是写个编译器,第一步是定义想要创造的语法。
test/exmaple.txt
int do_math(int a) {
int x = a * 5
return x + 3
}
echo(do_math(13))
echo(do_math(12))
上述这个语法跟C语言很像,只是每行少了;号。
安装三套件
首先安装flex、bison、llvm,分别用来进行词法分析、语法分析、构造AST及生成LLVM IR
$ brew install flex
$ brew install bison
$ brew install llvm
$ export PATH="/usr/local/opt/flex/bin:$PATH"
$ export PATH="/usr/local/opt/bison/bin:$PATH"
$ export PATH="/usr/local/opt/llvm/bin:$PATH"
使用Flex进行文法分析
面对一个源代码文件,编译器要做的第一件事就是扫描这个源文件,将其中包含的词法token解析出来。这个事情自己写代码用上一些正则表达式也可以搞定,但开源界已有了更好的选择Flex,一个快速的词法token扫描器。这个工具很简单,所有文档也就一页。
我们参考文档写词法定义文件。
token.l
%{
#include <string>
#include "node.h"
#include "parser.hpp"
#define STRING_TOKEN yylval.string = new std::string(yytext, yyleng)
#define KEYWORD_TOKEN(t) yylval.token = t
%}
%option noyywrap
%%
[ \t\n] ;
"extern" KEYWORD_TOKEN(TEXTERN); return TEXTERN;
"return" KEYWORD_TOKEN(TRETURN); return TRETURN;
[a-zA-Z_][a-zA-Z0-9_]* STRING_TOKEN; return TIDENTIFIER;
[0-9]+\.[0-9]* STRING_TOKEN; return TDOUBLE;
[0-9]+ STRING_TOKEN; return TINTEGER;
"=" KEYWORD_TOKEN(TEQUAL); return TEQUAL;
"==" KEYWORD_TOKEN(TCEQ); return TCEQ;
"!=" KEYWORD_TOKEN(TCNE); return TCNE;
"<" KEYWORD_TOKEN(TCLT); return TCLT;
"<=" KEYWORD_TOKEN(TCLE); return TCLE;
">" KEYWORD_TOKEN(TCGT); return TCGT;
">=" KEYWORD_TOKEN(TCGE); return TCGE;
"(" KEYWORD_TOKEN(TLPAREN); return TLPAREN;
")" KEYWORD_TOKEN(TRPAREN); return TRPAREN;
"{" KEYWORD_TOKEN(TLBRACE); return TLBRACE;
"}" KEYWORD_TOKEN(TRBRACE); return TRBRACE;
"." KEYWORD_TOKEN(TDOT); return TDOT;
"," KEYWORD_TOKEN(TCOMMA); return TCOMMA;
"+" KEYWORD_TOKEN(TPLUS); return TPLUS;
"-" KEYWORD_TOKEN(TMINUS); return TMINUS;
"*" KEYWORD_TOKEN(TMUL); return TMUL;
"/" KEYWORD_TOKEN(TDIV); return TDIV;
. printf("Unknown token!\n"); yyterminate();
%%
可以看到上面一段%{和%}是cpp代码,引入了一些头文件,定了一些宏。
接着是%option noyywrap,说明扫描完一个文件后即停止。
再接着就是最关键的一段了,在%%与%%之间。左侧是每个词法token匹配的正则,右侧是对于匹配到的词法token,返回对应的token常量。这里注意,如果是关键字token,不仅要返回token常量前要设置好yylval.token。如果是标识符、数字常量token,则要在返回token常量前设置好yylval.string。如果上述所有正则都没匹配到,则说明出现了未知的词法token,词法解析中止。
使用Bison进行语法分析
词法分析完成后,编译器面对的是一个个词法token,编译器要弄懂这些词法token究竟表达什么意义,这时就要进行语法分析了。怎么将理解出来的语法含义用数据结构表达出来,当然是用AST(抽象语法树)。AST(抽象语法树)既然是一颗树,树上就会有很多节点,这些节点根据语义的不同还需要是不同的类型,因此需要设计一下AST(抽象语法树)上节点的语义单元类型,如下图所示:
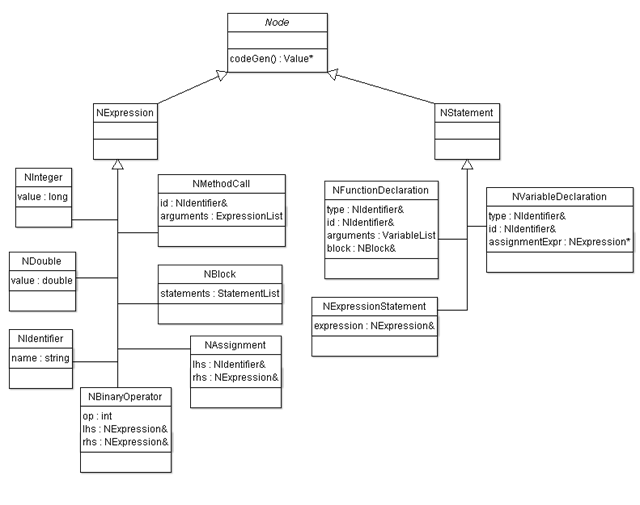
上图对应的cpp代码如下:
node.h
#include <iostream>
#include <vector>
#include <llvm/IR/Value.h>
class CodeGenContext;
class NStatement;
class NExpression;
class NVariableDeclaration;
typedef std::vector<NStatement*> StatementList;
typedef std::vector<NExpression*> ExpressionList;
typedef std::vector<NVariableDeclaration*> VariableList;
class Node {
public:
virtual ~Node() {}
virtual llvm::Value* codeGen(CodeGenContext& context) { return NULL; }
};
class NExpression : public Node {
};
class NStatement : public Node {
};
class NInteger : public NExpression {
public:
long long value;
NInteger(long long value) : value(value) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NDouble : public NExpression {
public:
double value;
NDouble(double value) : value(value) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NIdentifier : public NExpression {
public:
std::string name;
NIdentifier(const std::string& name) : name(name) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NMethodCall : public NExpression {
public:
const NIdentifier& id;
ExpressionList arguments;
NMethodCall(const NIdentifier& id, ExpressionList& arguments) :
id(id), arguments(arguments) { }
NMethodCall(const NIdentifier& id) : id(id) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NBinaryOperator : public NExpression {
public:
int op;
NExpression& lhs;
NExpression& rhs;
NBinaryOperator(NExpression& lhs, int op, NExpression& rhs) :
lhs(lhs), rhs(rhs), op(op) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NAssignment : public NExpression {
public:
NIdentifier& lhs;
NExpression& rhs;
NAssignment(NIdentifier& lhs, NExpression& rhs) :
lhs(lhs), rhs(rhs) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NBlock : public NExpression {
public:
StatementList statements;
NBlock() { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NExpressionStatement : public NStatement {
public:
NExpression& expression;
NExpressionStatement(NExpression& expression) :
expression(expression) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NReturnStatement : public NStatement {
public:
NExpression& expression;
NReturnStatement(NExpression& expression) :
expression(expression) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NVariableDeclaration : public NStatement {
public:
const NIdentifier& type;
NIdentifier& id;
NExpression *assignmentExpr;
NVariableDeclaration(const NIdentifier& type, NIdentifier& id) :
type(type), id(id) { assignmentExpr = NULL; }
NVariableDeclaration(const NIdentifier& type, NIdentifier& id, NExpression *assignmentExpr) :
type(type), id(id), assignmentExpr(assignmentExpr) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NExternDeclaration : public NStatement {
public:
const NIdentifier& type;
const NIdentifier& id;
VariableList arguments;
NExternDeclaration(const NIdentifier& type, const NIdentifier& id,
const VariableList& arguments) :
type(type), id(id), arguments(arguments) {}
virtual llvm::Value* codeGen(CodeGenContext& context);
};
class NFunctionDeclaration : public NStatement {
public:
const NIdentifier& type;
const NIdentifier& id;
VariableList arguments;
NBlock& block;
NFunctionDeclaration(const NIdentifier& type, const NIdentifier& id,
const VariableList& arguments, NBlock& block) :
type(type), id(id), arguments(arguments), block(block) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
这个没有什么太多好说的,基本与上图是一一对应的,除了每个class有一个virtual llvm::*Value** codeGen(*CodeGenContext*& *context*);虚函数定义,这个是给后面生成LLVM IR预留的。
接下来就可以定义语法了。
parser.y
%{
#include "node.h"
#include <cstdio>
#include <cstdlib>
NBlock *programBlock; /* the top level root node of our final AST */
extern int yylex();
void yyerror(const char *s) { std::printf("Error: %s\n", s);std::exit(1); }
%}
/* Represents the many different ways we can access our data */
%union {
Node *node;
NBlock *block;
NExpression *expr;
NStatement *stmt;
NIdentifier *ident;
NVariableDeclaration *var_decl;
std::vector<NVariableDeclaration*> *varvec;
std::vector<NExpression*> *exprvec;
std::string *string;
int token;
}
/* Define our terminal symbols (tokens). This should
match our tokens.l lex file. We also define the node type
they represent.
*/
%token <string> TIDENTIFIER TINTEGER TDOUBLE
%token <token> TCEQ TCNE TCLT TCLE TCGT TCGE TEQUAL
%token <token> TLPAREN TRPAREN TLBRACE TRBRACE TCOMMA TDOT
%token <token> TPLUS TMINUS TMUL TDIV
%token <token> TRETURN TEXTERN
/* Define the type of node our nonterminal symbols represent.
The types refer to the %union declaration above. Ex: when
we call an ident (defined by union type ident) we are really
calling an (NIdentifier*). It makes the compiler happy.
*/
%type <ident> ident
%type <expr> numeric call_expr value_expr assign_expr operand_expr
%type <varvec> func_decl_args
%type <exprvec> call_args
%type <block> program stmts block
%type <stmt> stmt var_decl func_decl extern_decl
%type <token> comparison calculation
/* Operator precedence for mathematical operators */
%left TCGE
%left TCGT
%left TCLE
%left TCLT
%left TCNE
%left TCEQ
%left TMINUS
%left TPLUS
%left TDIV
%left TMUL
%start program
%%
program : stmts { programBlock = $1; }
;
stmts : stmt { $$ = new NBlock(); $$->statements.push_back($<stmt>1); }
| stmts stmt { $1->statements.push_back($<stmt>2); }
;
stmt : func_decl
| var_decl
| extern_decl
| call_expr { $$ = new NExpressionStatement(*$1); }
| assign_expr { $$ = new NExpressionStatement(*$1); }
| TRETURN call_expr { $$ = new NReturnStatement(*$2); }
| TRETURN value_expr { $$ = new NReturnStatement(*$2); }
;
block : TLBRACE stmts TRBRACE { $$ = $2; }
| TLBRACE TRBRACE { $$ = new NBlock(); }
;
var_decl : ident ident { $$ = new NVariableDeclaration(*$1, *$2); }
| ident ident TEQUAL call_expr { $$ = new NVariableDeclaration(*$1, *$2, $4); }
| ident ident TEQUAL value_expr { $$ = new NVariableDeclaration(*$1, *$2, $4); }
;
extern_decl : TEXTERN ident ident TLPAREN func_decl_args TRPAREN
{ $$ = new NExternDeclaration(*$2, *$3, *$5); delete $5; }
;
func_decl : ident ident TLPAREN func_decl_args TRPAREN block
{ $$ = new NFunctionDeclaration(*$1, *$2, *$4, *$6); delete $4; }
;
func_decl_args : /*blank*/ { $$ = new VariableList(); }
| var_decl { $$ = new VariableList(); $$->push_back($<var_decl>1); }
| func_decl_args TCOMMA var_decl { $1->push_back($<var_decl>3); }
;
ident : TIDENTIFIER { $$ = new NIdentifier(*$1); delete $1; }
;
numeric : TINTEGER { $$ = new NInteger(atol($1->c_str())); delete $1; }
| TDOUBLE { $$ = new NDouble(atof($1->c_str())); delete $1; }
;
assign_expr : ident TEQUAL call_expr { $$ = new NAssignment(*$<ident>1, *$3); }
| ident TEQUAL value_expr { $$ = new NAssignment(*$<ident>1, *$3); }
;
call_expr : ident TLPAREN call_args TRPAREN { $$ = new NMethodCall(*$1, *$3); delete $3; }
;
operand_expr: call_expr %prec TMUL
| value_expr %prec TCEQ
;
value_expr: ident { $<ident>$ = $1; }
| numeric
| TLPAREN value_expr TRPAREN { $$ = $2; }
| operand_expr calculation operand_expr %prec TMUL { $$ = new NBinaryOperator(*$1, $2, *$3); }
| operand_expr comparison operand_expr %prec TCEQ { $$ = new NBinaryOperator(*$1, $2, *$3); }
;
call_args : /*blank*/ { $$ = new ExpressionList(); }
| value_expr { $$ = new ExpressionList(); $$->push_back($1); }
| call_expr { $$ = new ExpressionList(); $$->push_back($1); }
| call_args TCOMMA value_expr { $1->push_back($3); }
| call_args TCOMMA call_expr { $1->push_back($3); }
;
comparison : TCEQ | TCNE | TCLT | TCLE | TCGT | TCGE;
calculation: TMUL | TDIV | TPLUS | TMINUS;
%%
上述这个文件定义了支持的各种语法结构,这里的核心是一条条语法规则,类似于BNF范式定义。这个感觉是最难看懂的一部分了,可以结合着YACC(BISON)使用指南看。
掌握了bison的用法,写语法定义文件不难,但很容易出现移位/归约冲突。这时就可以将冲突的示例打印出来仔细分析,并对语法定义文件进行调整了。
$ bison -d -o parser.cpp parser.y -Wcounterexamples
如果一切没什么问题,这时就可以生成语法解析cpp文件及词法扫描cpp文件了:
$ bison -d -o parser.cpp parser.y
$ lex -o tokens.cpp tokens.l
组装AST和生成LLVM IR
其实经过上面的步骤后,我们写个小程序就已经可以组装出AST了。
main.cpp
#include <iostream>
#include "node.h"
extern NBlock* programBlock;
extern int yyparse();
int main(int argc, char **argv)
{
yyparse();
std::cout << programBlock << endl;
return 0;
}
简单编译一下:
$ clang++ -o parser parser.cpp tokens.cpp main.cpp
再执行一下:
$ ./parser
这时应该就可以打印出programBlock这个AST树的根节点了。
但组装出AST不是我们的目标,我们的目标是将抽象语法树AST转换为机器码。这意味着将每一个语义节点转换成等价的机器指令。LLVM将帮助我们把这步变得非常简单,因为LLVM将真实的指令抽象成类似AST的指令。这意味着我们真正要做的事就是将AST转换成抽象指令。 你可以想象这个过程是从抽象语法树的根节点开始遍历每一个树上节点并产生字节码的过程。现在就是使用我们在Node中定义的codeGen方法的时候了。例如,当我们遍历NBlock代码的时候(语义上NBlock代表一组我们语言的语句的集合),我们将调用列表中每条语句的codeGen方法。上面步骤代码类似如下的形式:
Value* NBlock::codeGen(CodeGenContext& context)
{
StatementList::const_iterator it;
Value *last = NULL;
for (it = statements.begin(); it != statements.end(); it++) {
std::cout << "Generating code for " << typeid(**it).name() << endl;
last = (**it).codeGen(context);
}
std::cout << "Creating block" << endl;
return last;
}
在实现批量codeGen函数前,这里还实现一个简单的代码生成上下文对象,里面维护了一个简单的block栈。
codegen.h
#include <stack>
#include <typeinfo>
#include <llvm/IR/Module.h>
#include <llvm/IR/Function.h>
#include <llvm/IR/Type.h>
#include <llvm/IR/DerivedTypes.h>
#include <llvm/IR/LLVMContext.h>
#include <llvm/IR/LegacyPassManager.h>
#include <llvm/IR/Instructions.h>
#include <llvm/IR/CallingConv.h>
#include <llvm/IR/IRPrintingPasses.h>
#include <llvm/IR/IRBuilder.h>
#include <llvm/Support/TargetSelect.h>
#include <llvm/ExecutionEngine/ExecutionEngine.h>
#include <llvm/ExecutionEngine/MCJIT.h>
#include <llvm/ExecutionEngine/GenericValue.h>
#include <llvm/Support/raw_ostream.h>
#include <llvm/Bitcode/BitcodeWriter.h>
using namespace llvm;
class NBlock;
static LLVMContext MyContext;
class CodeGenBlock {
public:
BasicBlock *block;
Value *returnValue;
std::map<std::string, Value*> locals;
};
class CodeGenContext {
std::stack<CodeGenBlock *> blocks;
Function *mainFunction;
public:
Module *module;
CodeGenContext() { module = new Module("main", MyContext); }
void generateCode(NBlock& root, std::string bcFile);
GenericValue runCode();
std::map<std::string, Value*>& locals() { return blocks.top()->locals; }
BasicBlock *currentBlock() { return blocks.top()->block; }
void pushBlock(BasicBlock *block) { blocks.push(new CodeGenBlock()); blocks.top()->returnValue = NULL; blocks.top()->block = block; }
void popBlock() { CodeGenBlock *top = blocks.top(); blocks.pop(); delete top; }
void setCurrentReturnValue(Value *value) { blocks.top()->returnValue = value; }
Value* getCurrentReturnValue() { return blocks.top()->returnValue; }
};
最后为node.h中定义的每一种语义单元编写好codeGen代码实现。做这部分之前需要了解下LLVM IR,参考LLVM IR入门指南。
另外如何用cpp代码操作LLVM IR,暂时也找不到更好参考指引,要多参照llvm的examples研究,依葫芦画瓢。
codegen.cpp
#include "node.h"
#include "codegen.h"
#include "parser.hpp"
using namespace std;
/* Compile the AST into a module */
void CodeGenContext::generateCode(NBlock& root, std::string bcFile)
{
std::cout << "Generating code...\n";
/* Create the top level interpreter function to call as entry */
vector<Type*> argTypes;
FunctionType *ftype = FunctionType::get(Type::getInt32Ty(MyContext), makeArrayRef(argTypes), false);
mainFunction = Function::Create(ftype, GlobalValue::ExternalLinkage, "main", module);
BasicBlock *bblock = BasicBlock::Create(MyContext, "entry", mainFunction, 0);
/* Push a new variable/block context */
pushBlock(bblock);
root.codeGen(*this); /* emit bytecode for the toplevel block */
ReturnInst::Create(MyContext, ConstantInt::get(Type::getInt32Ty(MyContext), 0), bblock);
popBlock();
/* Print the bytecode in a human-readable format
to see if our program compiled properly
*/
std::cout << "Code is generated.\n";
legacy::PassManager pm;
pm.add(createPrintModulePass(outs()));
pm.run(*module);
std::error_code errInfo;
llvm::raw_ostream *out = new llvm::raw_fd_ostream(bcFile, errInfo, sys::fs::F_None);
llvm::WriteBitcodeToFile(*module, *out);
out->flush();
delete out;
}
/* Executes the AST by running the main function */
GenericValue CodeGenContext::runCode() {
std::cout << "Running code...\n";
ExecutionEngine *ee = EngineBuilder( unique_ptr<Module>(module) ).create();
ee->finalizeObject();
vector<GenericValue> noargs;
GenericValue v = ee->runFunction(mainFunction, noargs);
std::cout << "Code was run.\n";
return v;
}
/* Returns an LLVM type based on the identifier */
static Type *typeOf(const NIdentifier& type)
{
if (type.name.compare("int") == 0) {
return Type::getInt64Ty(MyContext);
}
else if (type.name.compare("double") == 0) {
return Type::getDoubleTy(MyContext);
}
return Type::getVoidTy(MyContext);
}
/* -- Code Generation -- */
Value* NInteger::codeGen(CodeGenContext& context)
{
std::cout << "Creating integer: " << value << endl;
return ConstantInt::get(Type::getInt64Ty(MyContext), value, true);
}
Value* NDouble::codeGen(CodeGenContext& context)
{
std::cout << "Creating double: " << value << endl;
return ConstantFP::get(Type::getDoubleTy(MyContext), value);
}
Value* NIdentifier::codeGen(CodeGenContext& context)
{
std::cout << "Creating identifier reference: " << name << endl;
if (context.locals().find(name) == context.locals().end()) {
std::cerr << "undeclared variable " << name << endl;
return NULL;
}
return new LoadInst(context.locals()[name], "", false, context.currentBlock());
}
Value* NMethodCall::codeGen(CodeGenContext& context)
{
Function *function = context.module->getFunction(id.name.c_str());
if (function == NULL) {
std::cerr << "no such function " << id.name << endl;
}
std::vector<Value*> args;
ExpressionList::const_iterator it;
for (it = arguments.begin(); it != arguments.end(); it++) {
args.push_back((**it).codeGen(context));
}
CallInst *call = CallInst::Create(function, makeArrayRef(args), "", context.currentBlock());
std::cout << "Creating method call: " << id.name << endl;
return call;
}
Value* NBinaryOperator::codeGen(CodeGenContext& context)
{
std::cout << "Creating binary operation " << op << endl;
Instruction::BinaryOps instr;
switch (op) {
case TPLUS: instr = Instruction::Add; goto math;
case TMINUS: instr = Instruction::Sub; goto math;
case TMUL: instr = Instruction::Mul; goto math;
case TDIV: instr = Instruction::SDiv; goto math;
/* TODO comparison */
}
return NULL;
math:
return BinaryOperator::Create(instr, lhs.codeGen(context),
rhs.codeGen(context), "", context.currentBlock());
}
Value* NAssignment::codeGen(CodeGenContext& context)
{
std::cout << "Creating assignment for " << lhs.name << endl;
if (context.locals().find(lhs.name) == context.locals().end()) {
std::cerr << "undeclared variable " << lhs.name << endl;
return NULL;
}
return new StoreInst(rhs.codeGen(context), context.locals()[lhs.name], false, context.currentBlock());
}
Value* NBlock::codeGen(CodeGenContext& context)
{
StatementList::const_iterator it;
Value *last = NULL;
for (it = statements.begin(); it != statements.end(); it++) {
std::cout << "Generating code for " << typeid(**it).name() << endl;
last = (**it).codeGen(context);
}
std::cout << "Creating block" << endl;
return last;
}
Value* NExpressionStatement::codeGen(CodeGenContext& context)
{
std::cout << "Generating code for " << typeid(expression).name() << endl;
return expression.codeGen(context);
}
Value* NReturnStatement::codeGen(CodeGenContext& context)
{
std::cout << "Generating return code for " << typeid(expression).name() << endl;
Value *returnValue = expression.codeGen(context);
context.setCurrentReturnValue(returnValue);
return returnValue;
}
Value* NVariableDeclaration::codeGen(CodeGenContext& context)
{
std::cout << "Creating variable declaration " << type.name << " " << id.name << endl;
AllocaInst *alloc = new AllocaInst(typeOf(type), NULL, id.name.c_str(), context.currentBlock());
context.locals()[id.name] = alloc;
if (assignmentExpr != NULL) {
NAssignment assn(id, *assignmentExpr);
assn.codeGen(context);
}
return alloc;
}
Value* NExternDeclaration::codeGen(CodeGenContext& context)
{
vector<Type*> argTypes;
VariableList::const_iterator it;
for (it = arguments.begin(); it != arguments.end(); it++) {
argTypes.push_back(typeOf((**it).type));
}
FunctionType *ftype = FunctionType::get(typeOf(type), makeArrayRef(argTypes), false);
Function *function = Function::Create(ftype, GlobalValue::ExternalLinkage, id.name.c_str(), context.module);
return function;
}
Value* NFunctionDeclaration::codeGen(CodeGenContext& context)
{
vector<Type*> argTypes;
VariableList::const_iterator it;
for (it = arguments.begin(); it != arguments.end(); it++) {
argTypes.push_back(typeOf((**it).type));
}
FunctionType *ftype = FunctionType::get(typeOf(type), makeArrayRef(argTypes), false);
Function *function = Function::Create(ftype, GlobalValue::InternalLinkage, id.name.c_str(), context.module);
BasicBlock *bblock = BasicBlock::Create(MyContext, "entry", function, 0);
context.pushBlock(bblock);
Function::arg_iterator argsValues = function->arg_begin();
Value* argumentValue;
for (it = arguments.begin(); it != arguments.end(); it++) {
(**it).codeGen(context);
argumentValue = &*argsValues++;
argumentValue->setName((*it)->id.name.c_str());
StoreInst *inst = new StoreInst(argumentValue, context.locals()[(*it)->id.name], false, bblock);
}
block.codeGen(context);
ReturnInst::Create(MyContext, context.getCurrentReturnValue(), bblock);
context.popBlock();
std::cout << "Creating function: " << id.name << endl;
return function;
}
上述文件中最上面的generateCode及runCode先不看,剩下的基本上全是为每一种语义单元编写好codeGen代码实现,将该语义单元翻译为对应的LLVM IR。
generateCode函数的作用是在最外层再包一个main函数,并将最终生成的LLVM IR字节码输出。
runCode函数的作用是使用LLVM自带的JIT执行引擎,直接运行LLVM IR字节码。
再然后这里写个main函数,将生成的LLVM IR字节码写入到文件中。
main.cpp
#include <iostream>
#include "codegen.h"
#include "node.h"
using namespace std;
extern FILE *yyin;
extern int yyparse();
extern NBlock *programBlock;
void createCoreFunctions(CodeGenContext &context);
int main(int argc, char **argv)
{
FILE *fp = fopen("test/example.txt", "r");
if (!fp)
{
printf("couldn't open file for reading\n");
exit(-1);
}
yyin = fp;
int parseErr = yyparse();
if (parseErr != 0) {
printf("couldn't complete lex parse\n");
exit(-1);
}
fclose(fp);
InitializeNativeTarget();
InitializeNativeTargetAsmPrinter();
InitializeNativeTargetAsmParser();
CodeGenContext context;
createCoreFunctions(context);
context.generateCode(*programBlock, "test/example.bc");
return 0;
}
这里还通过createCoreFunctions函数植入了一些内置核心函数。
编译出我们的编译器:
$ clang++ -std=c++14 -o compiler parser.cpp codegen.cpp main.cpp tokens.cpp corefn.cpp `llvm-config --libs` `llvm-config --ldflags` -lpthread -ldl -lz -lncurses -rdynamic
使用新鲜出炉的编译器将test/example.txt编译为test/example.bc:
$ ./compiler
test/example.bc中的内容就是LLVM IR的字节码了。
我们可以用LLVM JIT来执行一下:
$ lli test/example.bc
生成的bc文件不可读,可以用llvm-dis工具反解析一下得到人类可阅读的LLVM IR字节码:
$ llvm-dis < test/example.bc | less
编译出二进制并执行
最后将上面得到的LLVM IR字节码文件编译出二进制文件:
$ llc test/example.bc -o test/example.S # 先将LLVM IR字节码转成汇编代码
$ clang++ test/example.S -o test/example.native # 再用clang++将汇编代码编译为二进制文件
测试下二进制文件是否可以正常执行:
$ ./test/example.native
68
63
因为我们在语法定义文件里支持了链接外部函数,因此这里还支持调用cpp的函数,演示如下:
test/example.txt
extern void printi(int val)
int do_math(int a) {
int x = a * 5
return x + 3
}
echo(do_math(13))
echo(do_math(12))
printi(10)
这里声明了一个外部的函数printi,我们在cpp文件中实现它:
native.cpp
#include <cstdio>
extern "C"
void printi(long long val)
{
printf("%lld\n", val);
}
使用新鲜出炉的编译器将test/example.txt编译为test/example.bc:
$ ./compiler
将上面得到的LLVM IR字节码文件编译出二进制文件:
$ llc test/example.bc -o test/example.S # 先将LLVM IR字节码转成汇编代码
$ clang++ native.cpp test/example.S -o test/example.native # 再用clang++将汇编代码编译为二进制文件
测试下二进制文件是否可以正常执行:
$ ./test/example.native
68
63
10
至此,一个工具性质的编译器就完成了。
总结
在编写一个简易编译器的过程中,查阅了相关多的资料,学习并加强了编译原理相关的知识,对代码是如何运行的有了更深刻的认识,整个探究过程还挺有意思的。
本篇涉及的所有代码见toy-compiler。
参考
- https://gnuu.org/2009/09/18/writing-your-own-toy-compiler/
- https://coolshell.cn/articles/1547.html
- https://blog.csdn.net/wp1603710463/article/details/50365640
- https://github.com/Evian-Zhang/llvm-ir-tutorial
- https://stackoverflow.com/questions/3167751/how-to-solve-a-shift-reduce-conflict
- https://llvm.zcopy.site/
文章作者 Jeremy Xu
上次更新 2020-10-06
许可协议 © Copyright 2020 Jeremy Xu