解决pvc无法mount的问题
文章目录
这周遇到了两个因pvc无法attach导致pod一直没法正常启动的问题,这里记录一下解决的过程。
问题一
问题描述
一个deployment,在其spec中指定使用了某一个pvc,在很偶然的情况下,出现这一个deployment对应的pod被调度到了另外一个node节点,但pod在另外的node由于无法正常attach pv volume一直没法正常运行。
问题解决
首先检查一下有问题的pod:
$ kubectl describe pod xxxx
Warning FailedAttachVolume 43m attachdetach-controller Multi-Attach error for volume "pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512" Volume is already exclusively attached to one node and can't be attached to another
可以看到attachdetach-controller报告说这个volume已经被attach到一个node节点上了,因此不能被attach到其它的node节点。
然后检查一下这个volume被哪个node节点attach住了:
$ kubectl describe pv pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512
Source:
Type: RBD (a Rados Block Device mount on the host that shares a pod's lifetime)
...
RBDImage: kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512
...
RBDPool: k8s
...
这里可以看到这个volume对应的rbd镜像是kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512,rbd池是k8s。
接下来可以用ceph的相关命令查一下该rbd镜像现在被哪个node节点使用了:
$ rbd info k8s/kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512
rbd image 'kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512':
...
block_name_prefix: rbd_data.115f79643c9869
...
# 这里将上面的block_name_prefix属性值拿出来,将rbd_data修改为rbd_header即可
$ rados listwatchers -p k8s rbd_header.115f79643c9869
watcher=10.125.53.47:0/3423687629 client.1138525 cookie=18446462598732840965
上述命令就看到了这个rbd镜像是被10.125.53.47这个node节点使用了。
接下来登录到10.125.53.47这个node节点,消除其对rbd镜像的使用。
# 这里的路径为/dev/rbd/${rbdPool}/${rbdImage}
$ ls -l /dev/rbd/k8s/kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512
lrwxrwxrwx 1 root root 10 7月 2 11:30 /dev/rbd/k8s/kubernetes-dynamic-pvc-0a5eb91b-3720-11e8-8d2b-000c29f8a512 -> ../../rbd4
# 直接使用rbd unmap命令将rbd镜像unmap
$ rbd unmap /dev/rbd4
到此问题解决。
根源分析
首先回顾一下k8s里volume的挂载过程:
- provision,卷分配成功,这个操作由
PVController完成 - attach,卷挂载在对应worker node,这个操作为
AttachDetachController完成 - mount,卷挂载为文件系统并且映射给对应Pod,这个操作为
VolumeManager完成
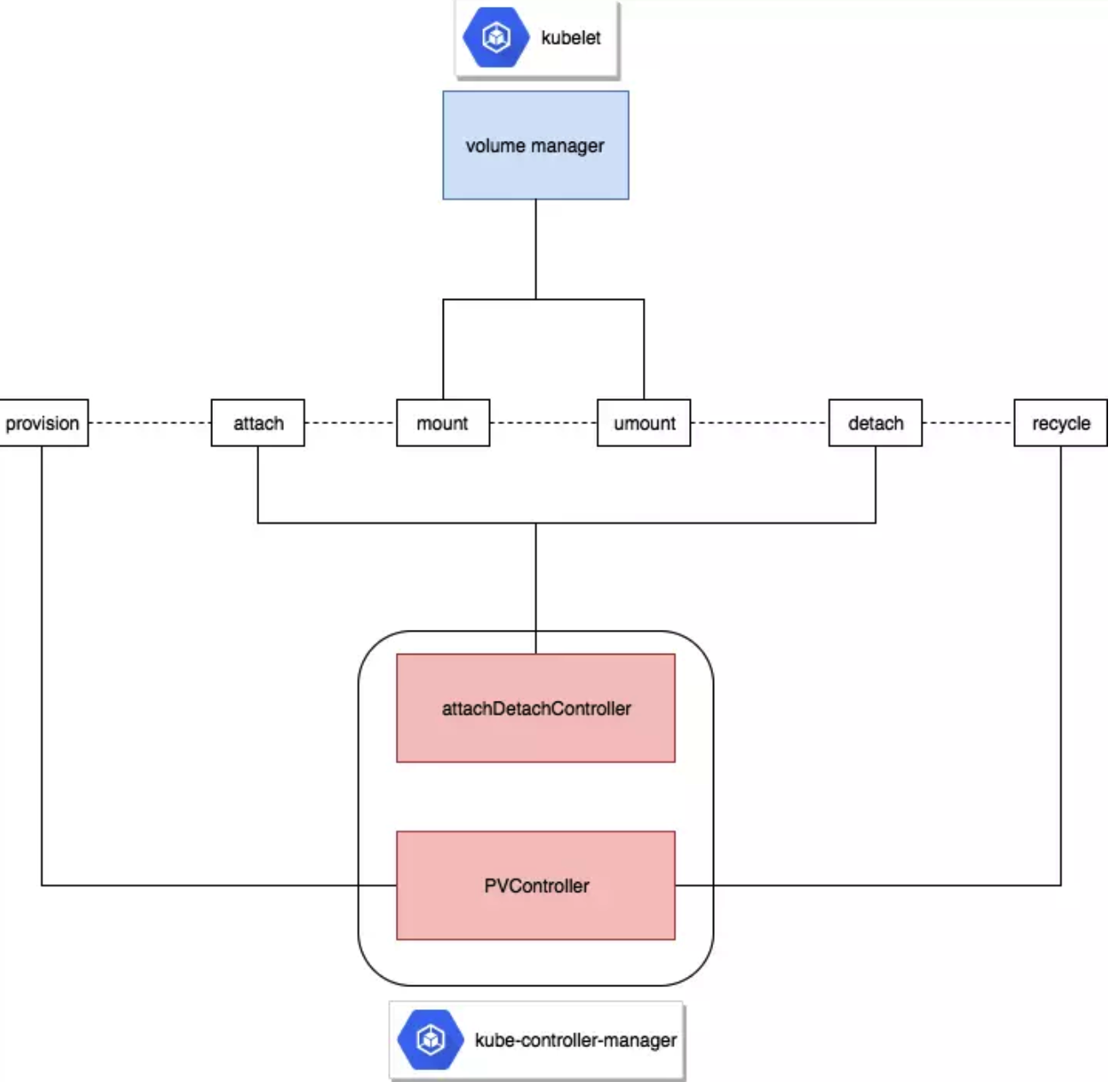
k8s里volume的卸载过程跟上述场景完全相反:
- umount,卷已经和对应worker node解除映射,且已经从文件系统umount
- detach,卷已经从worker node卸载
- recycle,卷被回收
在我这个场景里,pod的迁移会导致原来的pod从其node节点删除,这时AttachDetachController没有成为将rbd从原来的node节点detach。后面多次尝试却无法重现问题,猜测是当时由于某些原因AttachDetachController执行detach操作失败了,可能是强制删除pod导致的,所以删除pod时还是要慎用—force —grace-period=0选项。
问题二
问题描述
还是上述那个场景,这次对deployment作了一次滚动更新,这时k8s会新创建一个pod,尝试挂载volume,但这次原来那个node节点上pod仍处于Running状态,因而其使用volume是正常的。
问题解决
这次很容易解决,直接删除旧的pod就可以了:
$ kubectl delete pod xxxx
根源分析
很明显,滚动更新时产生多了一个pod,为什么会这样了,我们看一下deployment里的滚动更新策略:
$ kubectl get deployment xxxx -o yaml
...
deploySpec:
replicas: 1
...
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
volumes:
- name: data
persistentVolumeClaim:
claimName: data-vol
...
$ kubectl get pvc data-vol -o yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-vol
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: rbd
可以看到这里默认配置的滚动更新参数为maxSurge=1,也即允许比desired的pod数目多1个。而pvc又是ReadWriteOnce的访问模式,因此滚动更新时会产生多一个pod,而ReadWriteOnce的访问模式又不允许两个pod挂载同一个volume。
因此这里有几个的解决方案:
- 使用
ReadWriteMany访问模式的pvc - 将
maxSurge设置为0,避免在更新过程中产生多余的pod - 将deployment改为statefulset,statefulset对应的pod与pvc是一一绑定的,在更新过程中不会产生多余的pod
总结
kuberentes里使用存储自有其逻辑,按照它的逻辑去分析问题,很多问题都可以迎刃而解。
参考
文章作者 Jeremy Xu
上次更新 2019-07-07
许可协议 © Copyright 2020 Jeremy Xu