清除k8s使用underlay网络的障碍
文章目录
k8s中使用underlay网络的障碍
上一篇说到在k8s里使用underlay网络有一个弊端,使用了underlay网络的pod无法访问serviceIP,这一点可能通过修改修改业务应用的chart来解决,主要解决方法是:
- 使
kube-dns服务通过underlay网络直接可达,可以将coredns的pod设置为使用hostNetwork,然后修改kubelet里配置的--cluster-dns参数。 - 修改业务应用的chart,避免使用serviceIP,可以通过其它服务发现机制直接找到目标pod的podIP。
上述两个方案虽然可行,但需要进行一系列调整,成本确实比较高,如果业务应用的chart比较复杂,改造起来就更费劲了。
使用修改后的ptp解决上述问题
在网上偶然看到一篇文章,在这篇文章里讲到可以向已经使用了macvlan等underlay网络的pod中再插入一个ptp的网络接口,设置必要的路由规则后,即可实现在这种pod中也可以正常访问serviceIP。当然依旧是使用cni插件的方式实现的。Bingo, 这正是我需要的。
于是我参考unnumbered-ptp.go, 我实现了一个veth-to-host的cni插件,该插件的原理如下:
- 创建⼀对veth pair,⼀端挂⼊容器内,⼀端挂⼊宿主机内。
- 在容器内设置路由规则,当目标地址是宿主机IP或非underlay网络,则使用veth将数据包转出,nexthop地址是宿主机IP。
- 在宿主机内设置路由规则,当目标地址是容器的underlay网络IP时,使用veth将数据包转出, nexthop地址是容器的underlay网络IP。
然后原来的macvlan配合使用该cni插件,即可在使用了underlay网络的pod也可以正常访问serviceIP,cni的配置如下:
/etc/cni/net.d/10-cnichain.conflist
{
"name": "cni0",
"cniVersion": "0.3.1",
"plugins": [
{
"name": "mymacvlan",
"type": "macvlan",
"master": "enp5s0f0",
"ipam": {
"type": "host-local",
"subnet": "10.10.20.0/24",
"rangeStart": "10.10.20.50",
"rangeEnd": "10.10.20.60",
"gateway": "10.10.20.254",
"routes": [{
"dst": "0.0.0.0/0"
}]
}
},
{
"name": "myptp",
"type": "veth-to-host",
"hostInterface": "enp5s0f0",
"containerInterface": "veth0",
"ipMasq": true
}
]
}
这里有几点要注意一下:
- veth-to-host cni插件的二进制文件需要放入
CNI_BIN_PATH目录中 - 上述的cni配置是一个链式配置,一定要注意顺序,
macvlan等underlay网络的cni配置要放在前面
应用了上述cni配置后,一般来说可以正常工作了。如果我们对实现原理比较好奇的话,可以简单创建一个pod,执行以下命令观察创建的网络接口和各种路由规则:
# 检查pod容器里的网络接口
[root@node-1 ~]# kubectl -n demo exec -ti redis-predixy-67d989bdd9-p7fbf sh
/ # ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 2e:31:a0:bc:39:20 brd ff:ff:ff:ff:ff:ff
4: veth0@if139: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 46:4a:fd:d5:3a:bf brd ff:ff:ff:ff:ff:ff
# 检查pod容器里的路由规则
/ # ip route show
default via 10.10.20.152 dev veth0
10.10.20.0/24 dev eth0 scope link src 10.10.20.53
10.10.20.152 dev veth0 scope link
# 退出pod容器
/ # exit
# 检查宿主机里的网络接口
[root@node-1 ~]# ip link show
...
139: vetha0e043dd@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 12:78:cc:ea:9b:26 brd ff:ff:ff:ff:ff:ff link-netnsid 3
...
# 检查宿主机主表里的路由规则
[root@node-1 ~]# ip route show
...
10.10.20.53 dev vetha0e043dd scope link
...
# 检查宿主机的自定义路由表
[root@node-1 ~]# ip rule show
...
1024: from all iif vetha0e043dd lookup 596
...
# 检查宿主机上自定义路由表中的路由规则
[root@node-1 ~]# ip route show table 596
default via 10.10.20.53 dev vetha0e043dd
从上述输出可以看出确实与该CNI插件的原理是一致的。
开发cni插件的一般过程
上面实际的开发了一个崭新的cni插件,下面总结一下开发cni插件的过程:
首先是画好网络拓扑图,示例如下。在这个拓扑图中要将同宿主机上的pod之间、pod及宿主机、跨主机上的pod之间网络流量如何流转描述清楚,这里需要了解较多的网络知识,如网络的二三层、路由表、nat、bridge、openvswith、sdn、policy route等。
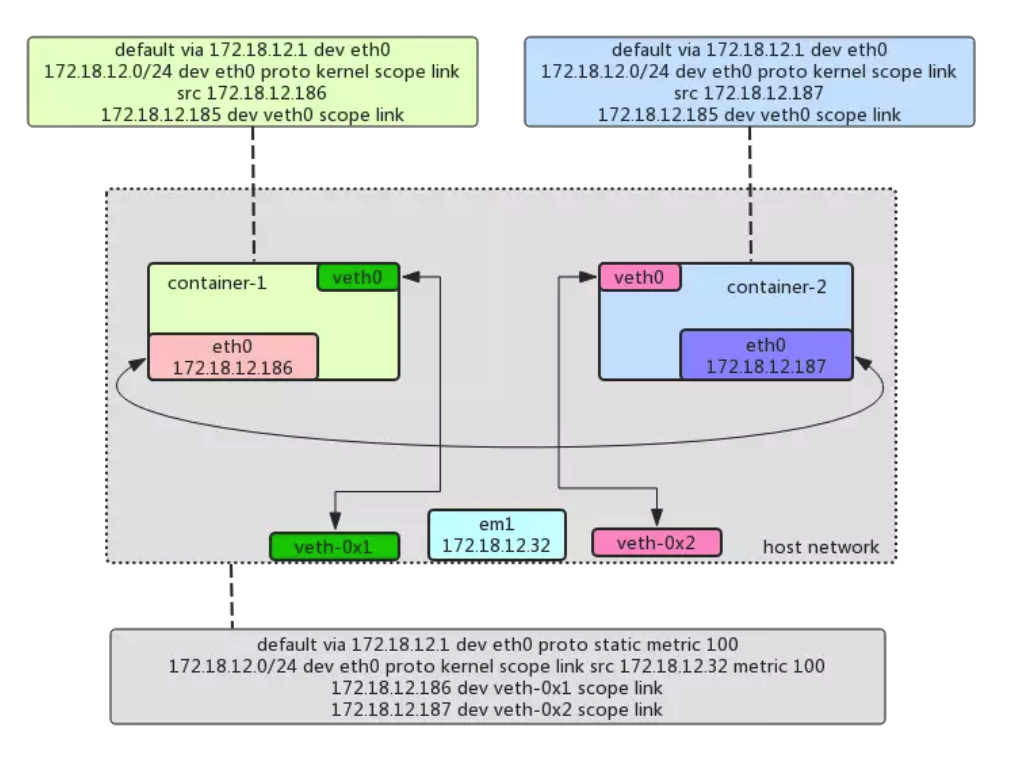
然后到cni官方插件这里找一找,看看有没有满足需求的现成cni插件。除非需求很特殊,一般是可以找到现成插件的。
如果找不到现在插件,可以参考cni插件示例编写新的cni插件,主要就是按网络拓扑图里设想的方案实现
cmdAdd、cmdDel等方法,这些方法的主要逻辑就是按设想创建网络接口、设置路由规则、设置NAT规则等。编写好cni插件后,编译出cni插件的二进制文件,可以本地先测试一下:
# 提前将二进制文件放入CNI_PATH目录下,配置好/etc/cni/net.d目录下的cni配置文件 # 下面会创建一个网络命名空间,并调用cni插件尝试为该网络命名空间配置好网络 ip netns add test CNI_PATH=/usr/local/bin NETCONFPATH=/etc/cni/net.d /usr/local/bin/cnitool add cni0 /var/run/netns/test # 进入网络命名空间,检查网络接口、路由表信息 ip netns exec test sh .... # 在宿主机检查网络接口、路由表信息 ip link show ip route show ip rule show iptables -t nat -L -n iptables -L -n检查结果如果没有什么大的问题,跟设想一致的话,这个cni插件就差不多了。
接下来可以创建两个跨主机的pod再检查一下。
如果可以的话,写点单元测试就更好了,参考这里。
最后记得为新写的cni插件写个文档,参考这里。
总结
总的来说,开发一个cni网络插件过程还是挺清晰的,也比较简单,本周也算是又掌握一门技能。
参考
文章作者 Jeremy Xu
上次更新 2019-06-30
许可协议 © Copyright 2020 Jeremy Xu