MySQL InnoDB Cluster实战
文章目录
对于MySQL的高可用集群方案,之前在项目实战中使用过简单的主从半同步复制方案、基于Galera的MySQL高可用集群,但总感觉配置太复杂,集群目前的状况不太清晰明确,发生故障转移时经常需要人工参与。这周使用mysql-operator,发现这里已经使用了MySQL官方推出的一套完整的、高可用的MySQL解决方案-MySQL InnoDB Cluster,这绝对是MySQL运维工程师的福音,这里将一些研究过程中查阅的资料记录一下。
MySQL InnoDB Cluster简介
MySQL InnoDB Cluster 是最新GA的MySQL高可用方案,利用MySQL Group Replication和MySQL Shell、MySQL Router可以轻松搭建强壮的高可用方案。
MySQL Shell 是新的mysql 客户端工具支持x protocol和mysql protocol,具备JavaScript和python可编程能力,作为搭建InnoDB Cluster管理工具。
MySQL Router 是访问路由转发中间件,提供应用程序访问的failover能力。
MySQL InnoDB cluster provides a complete high availability solution for MySQL. MySQL Shell includes AdminAPI which enables you to easily configure and administer a group of at least three MySQL server instances to function as an InnoDB cluster. Each MySQL server instance runs MySQL Group Replication, which provides the mechanism to replicate data within InnoDB clusters, with built-in failover. AdminAPI removes the need to work directly with Group Replication in InnoDB clusters, but for more information see Chapter 17, Group Replication which explains the details. MySQL Router can automatically configure itself based on the cluster you deploy, connecting client applications transparently to the server instances. In the event of an unexpected failure of a server instance the cluster reconfigures automatically. In the default single-primary mode, an InnoDB cluster has a single read-write server instance - the primary. Multiple secondary server instances are replicas of the primary. If the primary fails, a secondary is automatically promoted to the role of primary. MySQL Router detects this and forwards client applications to the new primary. Advanced users can also configure a cluster to have multiple-primaries.
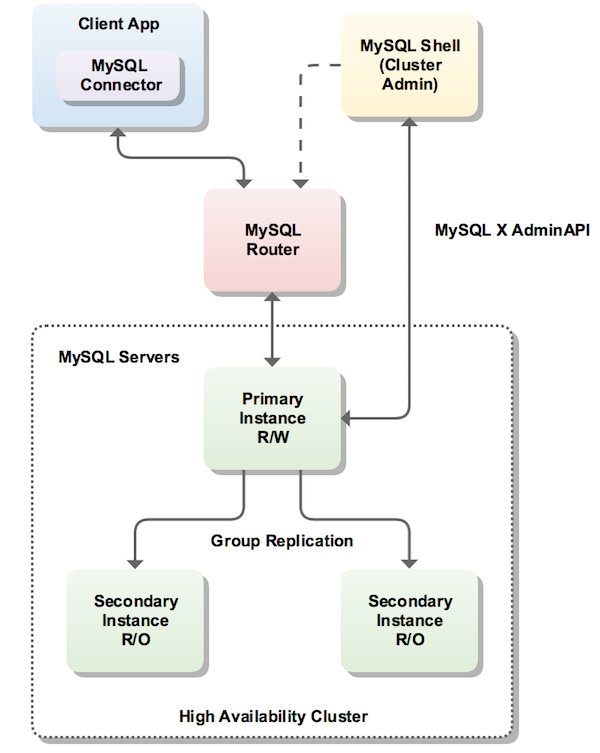
上面这张图看着比较清楚,通过MySQL Shell可以配置出一个高可用自动进行故障转移的MySQL InnoDB Cluster,在后续运维过程中也可以通过MySQL Shell对集群进行状态监控及管理维护。通过MySQL Router向应用层屏蔽底层集群的细节,以应用层将普通的MySQL协议访问集群。
MySQL Group Replication 是最新GA的同步复制方式,具有以下特点:
- 支持单主和多主模式
- 基于Paxos算法,实现数据复制的一致性
- 插件化设计,支持插件检测,新增节点小于集群当前节点主版本号,拒绝加入集群,大于则加入,但无法作为主节点
- 没有第三方组件依赖
- 支持全链路SSL通讯
- 支持IP白名单
- 不依赖网络多播
搭建MySQL InnoDB Cluster
这里准备了3台虚拟机mysql-host1、mysql-host2、mysql-host3,IP分别为192.168.33.21、192.168.33.22、192.168.33.23。
安装软件包
第一步是在三台虚拟机上均安装mysql-community-server、mysql-shell、mysql-router软件包。
# 配置mysql的yum源
$ yum install -y https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
# 安装
$ yum install -y mysql-community-server mysql-shell mysql-router
配置主机名称映射
为保证三台虚拟机上可正常通过名称解析到对方的IP,这里将主机名称映射写入hosts文件中
$ cat << EOF >> /etc/hosts
192.168.33.21 mysql-host1
192.168.33.22 mysql-host2
192.168.33.23 mysql-host3
EOF
修改root密码
为了后续操作方便,这里修改三台虚拟机上MySQL的root密码
# 首先得到初始的root密码
$ systemctl start mysqld
$ ORIGINAL_ROOT_PASSWORD=$(awk '/temporary password/{print $NF}' /var/log/mysqld.log)
# 这里将mysql的root密码修改为R00T@mysql,这个密码符合复杂度要求
$ MYSQL_PWD="$ORIGINAL_ROOT_PASSWORD" mysql --connect-expired-password -e "ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'R00T@mysql';"
# 顺便允许mysql可在其它主机登录过来
$ MYSQL_PWD="$ORIGINAL_ROOT_PASSWORD" mysql --connect-expired-password -e "CREATE USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'R00T@mysql';"
$ MYSQL_PWD="$ORIGINAL_ROOT_PASSWORD" mysql --connect-expired-password -e "GRANT ALL ON *.* TO 'root'@'%' WITH GRANT OPTION; FLUSH PRIVILEGES;"
配置本地实例
MySQL InnoDB Cluster底层依赖Group Replication模式,而配置Group Replication模式首先要通过dba.configureLocalInstance设置每台虚拟机上的本地实例必要参数并持久化配置。
# 通过mysqlsh即可轻松完成本机实例的配置
$ cat << EOF > config_local_instance.js
dba.configureLocalInstance('root@localhost:3306', {'password': 'R00T@mysql', 'interactive': false})
EOF
$ mysqlsh --no-password --js --file=config_local_instance.js
# 重启后才能生效
$ systemctl restart mysqld
# 再检查一下本地实例配置的状况
$ cat << EOF > config_local_instance.js
dba.checkLocalInstance('root@localhost:3306', {'password': 'R00T@mysql', 'interactive': false})
EOF
$ mysqlsh --no-password --js --file=check_local_instance.js
初始化MySQL InnoDB Cluster
只需在mysql-host1这台虚拟机上进行以下操作就可以了。
$ cat << EOF > init_cluster.js
shell.connect('root@localhost:3306', 'R00T@mysql')
dba.createCluster('mycluster', {'localAddress': '192.168.33.21'})
var cluster=dba.getCluster('mycluster')
cluster.addInstance('root@192.168.33.22:3306', {'localAddress': '192.168.33.22', 'password': 'R00T@mysql'})
cluster.addInstance('root@192.168.33.23:3306', {'localAddress': '192.168.33.23', 'password': 'R00T@mysql'})
EOF
$ mysqlsh --no-password --js --file=init_cluster.js
初始化mysql-router
为了向应用层屏蔽底层集群的细节,我们还可以在三台虚拟机上均部署mysql-router。
# 以当前集群信息创建mysql-router的配置信息,注意这里密码R00T@mysql被编码为R00T%40mysql
$ mysqlrouter --bootstrap root:R00T%40mysql@192.168.33.21:3306 --user=mysqlrouter
# 重启mysqlrouter服务
$ systemctl restart mysqlrouter
部署验证
至此整套MySQL InnoDB Cluster就部署好了,我们在其它节点以MySQL协议即可访问该MySQL集群。
$ mysql -h192.168.33.21 -P3306 -uroot -pR00T@mysql
因为三台虚拟机上均安装了mysql-router,因此这里的IP三台虚拟机的IP均可,更好的办法用haproxy或nginx再做一下4层代理,由vip或LVS保证负载均衡器无单点故障,这个就是常规方案,按下不表了。
这里还以Vagrant及Ansible脚本的方式,整理了上述部署方案,参见这里。
运维中可能遇到的问题
同样在运维MySQL InnoDB Cluster时还是会遇到一些需要手工处理的场景,这里简要列举一下。
重启节点后需要手动重新加入集群
mysql-js> var cluster = dba.getCluster("mycluster")
mysql-js> cluster.status()
{
...
"192.168.33.23:3306": {
"address": "192.168.33.23:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "(MISSING)"
}
}
}
}
mysql-js> cluster.rejoinInstance('root@192.168.33.23:3306')
mysql-js> cluster.status()
{
...
"192.168.33.23:3306": {
"address": "192.168.33.23:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
}
}
集群所有节点发生重启
当集群的所有节点都offline,直接获取集群信息失败,如何重新恢复集群
mysql-js> var cluster=dba.getCluster('mycluster')
Dba.getCluster: This function is not available through a session to a standalone instance (RuntimeError)
执行rebootClusterFromCompleteOutage命令,可恢复集群
mysql-js> dba.rebootClusterFromCompleteOutage('mycluster')
Reconfiguring the cluster 'mycluster' from complete outage...
The instance '192.168.33.22:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
The instance '192.168.33.23:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
The cluster was successfully rebooted.
脑裂场景
当集群中有部分节点出现UNREACHABLE状态,此时集群无法做出决策,,会出现以下局面,此时只剩下一个活跃节点,此节点只能提供查询,无法写入,执行写入操作会hang住。
mysql-js> cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "192.168.33.21:3306",
"status": "NO_QUORUM",
"statusText": "Cluster has no quorum as visible from '192.168.33.21:3306' and cannot process write transactions. 2 members are not active",
"topology": {
"192.168.33.21:3306": {
"address": "192.168.33.21:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"192.168.33.22:3306": {
"address": "192.168.33.22:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "UNREACHABLE"
},
"192.168.33.23:3306": {
"address": "192.168.33.23:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "(MISSING)"
}
}
}
}
修复这种状态,需要执行forceQuorumUsingPartitionOf指定当前活跃节点(如果是多个则选择primary node),此时活跃节点可以提供读写操作,然后将其他节点加入此集群。
mysql-js> cluster.forceQuorumUsingPartitionOf('root@192.168.33.21:3306')
Restoring replicaset 'default' from loss of quorum, by using the partition composed of [192.168.33.21:3306]
Please provide the password for 'root@192.168.33.21:3306':
Restoring the InnoDB cluster ...
The InnoDB cluster was successfully restored using the partition from the instance 'root@10.186.23.94:3306'.
WARNING: To avoid a split-brain scenario, ensure that all other members of the replicaset are removed or joined back to the group that was restored.
mysql-js> cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "192.168.33.21:3306",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 2 members are not active",
"topology": {
"192.168.33.21:3306": {
"address": "192.168.33.21:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"192.168.33.22:3306": {
"address": "192.168.33.22:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "(MISSING)"
},
"192.168.33.23:3306": {
"address": "192.168.33.23:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "(MISSING)"
}
}
}
}
mysql-js> cluster.rejoinInstance('root@192.168.33.22:3306')
mysql-js> cluster.rejoinInstance('root@192.168.33.23:3306')
节点有哪状态
- ONLINE - 节点状态正常。
- OFFLINE - 实例在运行,但没有加入任何Cluster。
- RECOVERING - 实例已加入Cluster,正在同步数据。
- ERROR - 同步数据发生异常。
- UNREACHABLE - 与其他节点通讯中断,可能是网络问题,可能是节点crash。
- MISSING 节点已加入集群,但未启动group replication
集群有哪些状态
- OK – 所有节点处于online状态,有冗余节点。
- OK_PARTIAL – 有节点不可用,但仍有冗余节点。
- OK_NO_TOLERANCE – 有足够的online节点,但没有冗余,例如:两个节点的Cluster,其中一个挂了,集群就不可用了。
- NO_QUORUM – 有节点处于online状态,但达不到法定节点数,此状态下Cluster无法写入,只能读取。
- UNKNOWN – 不是online或recovering状态,尝试连接其他实例查看状态。
- UNAVAILABLE – 组内节点全是offline状态,但实例在运行,可能实例刚重启还没加入Cluster。
总结
总的来说,MySQL InnoDB Cluster相对于之前的集群方案还是要方便不少的,不过手工部署还是挺费时间的,看官们如果对手工部署感兴趣,也可以参考我整理出的anisble脚本,在Kubernetes环境快速部署MySQL InnoDB Cluster还是推荐直接使用mysql-operator。
参考
文章作者 Jeremy Xu
上次更新 2019-05-26
许可协议 © Copyright 2020 Jeremy Xu