PosgreSQL高可用集群实践
文章目录
工作中一个第三方软件使用了Posgresql数据库,而在我们的场景里,我们需要保证Posgresql数据库的高可用,网上查找了一下,发现stolon这个高可用,在使用前,先研究一下它的原理。
Stolon的架构
Stolon is composed of 3 main components
- keeper: it manages a PostgreSQL instance converging to the clusterview computed by the leader sentinel.
- sentinel: it discovers and monitors keepers and proxies and computes the optimal clusterview.
- proxy: the client’s access point. It enforce connections to the right PostgreSQL master and forcibly closes connections to old masters.
For more details and requirements see Stolon Architecture and Requirements
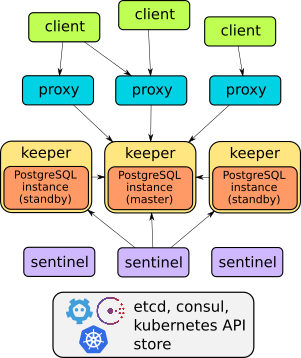
上面是Stolon项目Readme中的说明,可以看到其本质与Redis Sentinel的方案比较类似,都是哨兵模式。
由sentinel组件发现、观察keeper与proxy的信息,并计算出最优的集群视图。
每个keeper组件管理一个posgresql实例,并根据sentinel计算出的最优集群视图,将posgresql集群中各实例加以配置,最实现集群的最优方案。
除此之外,为了让客户端能透明地访问Posgresql集群,还提供了proxy组件处理客户端请求,最请求导向集群的master节点,这一点比redis sentinel方案更好了,就不用客户端驱动专门做sentinel模式支持了。
Stolon安装
官方文档中有写如何在kubernetes集群中部署Stolon集群,虽然也是用yaml文件分别3个组件,不过还是麻烦了些,幸好找到了对应的helm chart。
这样部署Stolon集群就很简单了:
git clone https://github.com/lwolf/stolon-chart
cd stolon-chart/stolon
helm install --namespace test --name stolon . --set store.backend=kubernetes --set persistence.enabled=true --set persistence.storageClassName=defaultScName
stolon-chart里使用storageclass的方式不太合规,顺便改了下,给它们发了个PR,不过貌似没有回应
然后kubernetes集群内部的其它pod配置stolon-proxy的service FQDN地址就可以访问到它了,比如用上面的命令部署的stolon集群可以以下面的地址来访问它:
stolon-stolon-proxy.test.svc.cluster.local:5432
验证高可用
既然是解决高可用性问题,光看看官方文档就这么部署了,还是不放心的,还是要模拟一下出问题的场景。官方文档里讲了验证的方法:
In a single node setup we can kill the current master keeper pod but usually the statefulset controller will recreate a new pod before the sentinel declares it as failed. To avoid the restart we’ll first remove the statefulset without removing the pod and then kill the master keeper pod. The persistent volume will be kept so we’ll be able to recreate the statefulset and the missing pods will be recreated with the previous data.
kubectl delete statefulset stolon-keeper --cascade=false kubectl delete pod stolon-keeper-0You can take a look at the leader sentinel log and will see that after some seconds it’ll declare the master keeper as not healthy and elect the other one as the new master:
no keeper info available db=cb96f42d keeper=keeper0 no keeper info available db=cb96f42d keeper=keeper0 master db is failed db=cb96f42d keeper=keeper0 trying to find a standby to replace failed master electing db as the new master db=087ce88a keeper=keeper1Now, inside the previous
psqlsession you can redo the last select. The first timepsqlwill report that the connection was closed and then it successfully reconnected:postgres=# select * from test; server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. postgres=# select * from test; id | value ----+-------- 1 | value1 (1 row)
就是删掉一个master节点的stolon-keeper组件,然后看sentinel的日志,可以很明显地看到一个新的master节点被选举出来了,这时posgresql客户端用原来的地址连上新的master节点了,验证成功了。
这里又学到一个小技巧,删除deployment、statefulset等时,加上--cascade=false可以保留住与这些资源对应的pod。
参考
文章作者 Jeremy Xu
上次更新 2019-03-15
许可协议 © Copyright 2020 Jeremy Xu