docker的两个bug
文章目录
这几天在工作中使用docker发现了docker的两个bug,这里记录下以备忘。
docker容器生成僵尸进程
现象
公司开发服务器上使用docker跑了几个容器,这些容器都是长时间运行的。偶然发现服务器上有大量僵尸进程,大约有两三千个。简单跟踪了下,发现这些僵尸进程均是在容器的进程命名空间的。
ps aux | grep 'Z' | grep -v grep
ll /proc/${any_zombie_pid}
在容器里运行的程序是很正常的web server,怎么会这样呢?在网上搜索了下,终于找到了答案:
初始进程的责任:“收割”“僵尸进程”
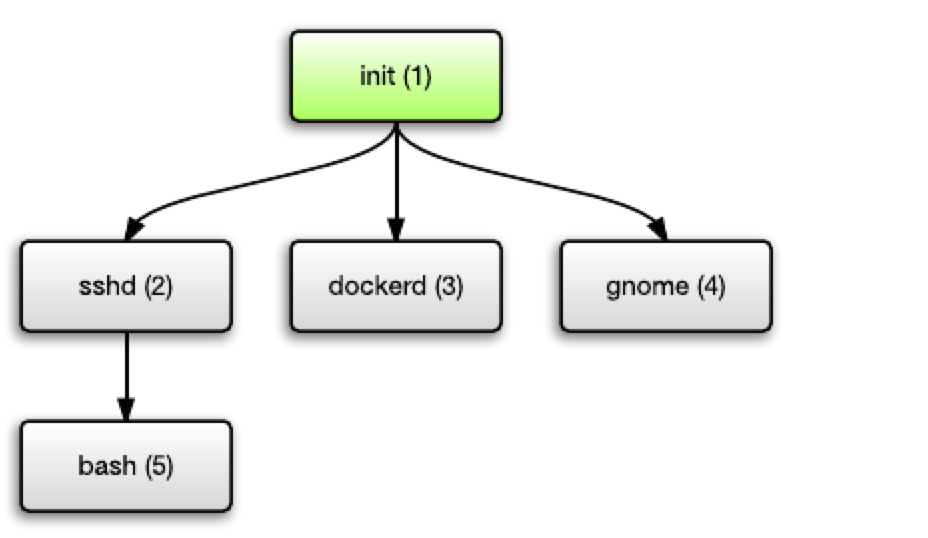
Unix 的进程之间是树状结构的关系。每个进程都可以派生出子进程,而除了最顶端的进程之外,也都会有一个父进程。
这个最顶端的进程就是初始进程,其在启动系统时被内核启动,并负责启动系统的其余功能部分。如:SSH 后台程序、Docker 后台程序、Apache/Nginx 和 GUI 桌面环境等等。这些程序又可能会派生出它们自己的子进程。
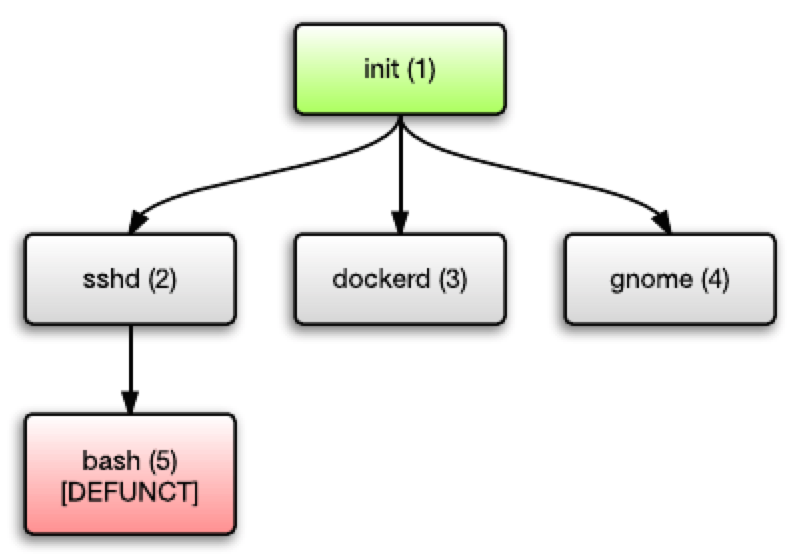
这一部分并没有什么问题。但问题在于当一个进程终止时,会发生什么?假设上图中的 bash (5) 进程结束了,那么其会转变为「废弃进程」(defunct process),也被称作为“僵尸进程”(zombie process)。
为什么会这样?因为 Unix 这样设计地目的,在于让父进程能够耐心“等待”子进程结束,从而获得其结束状态(exit status)。只有当父进程调用 waitpid() 之后,“僵尸进程”才会真正结束。手册里是这样描述地:
一个已经终止但并未被“等待”的进程,就成为了一个“僵尸”。内核会记录这些“僵尸进程”的基本信息(PID、终止状态、资源占用信息),以确保其父进程在之后的时间里可以通过“等待”来获取这个子进程的信息。
通常来说,人们会简单地认为“僵尸进程”就是那些会造成破坏的失控进程。但从 Unix 系统角度来分析,“僵尸进程”有着非常清晰地定义:进程已经终止,但尚未被其父进程“等待”。
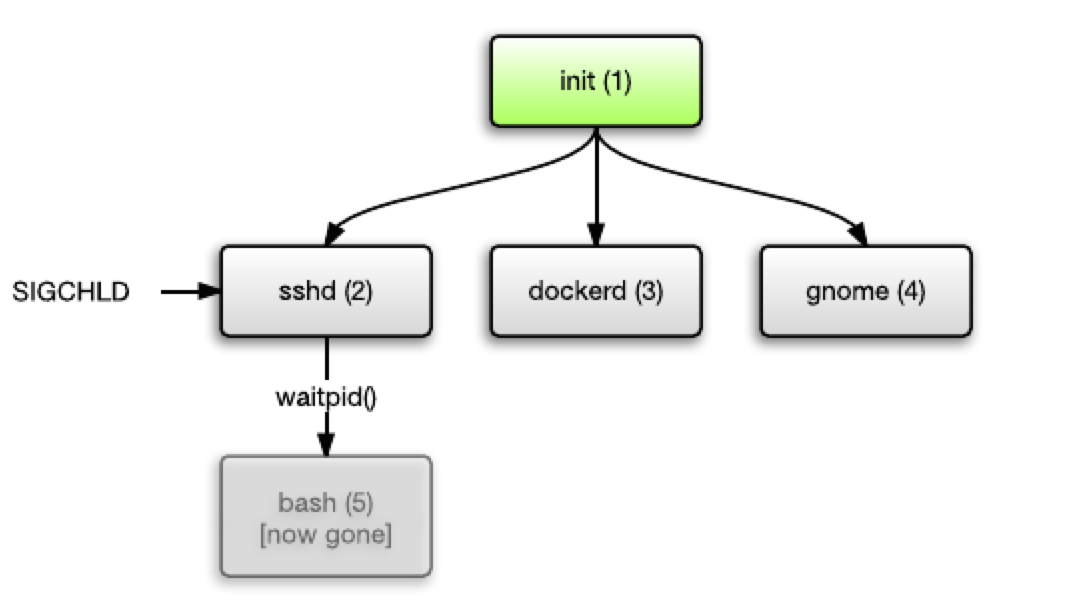
绝大多数情况下,这都不会产生什么问题。在一个子进程上调用
waitpid()以消除其“僵尸”状态,被称为“收割”。多数应用程序都能够正确地“收割”其子进程。在上例中,操作系统会在 bash 进程终止时发送 SIGCHLD 信号以唤醒 sshd 进程,其在接收到信号后就“收割”掉了此子进程。
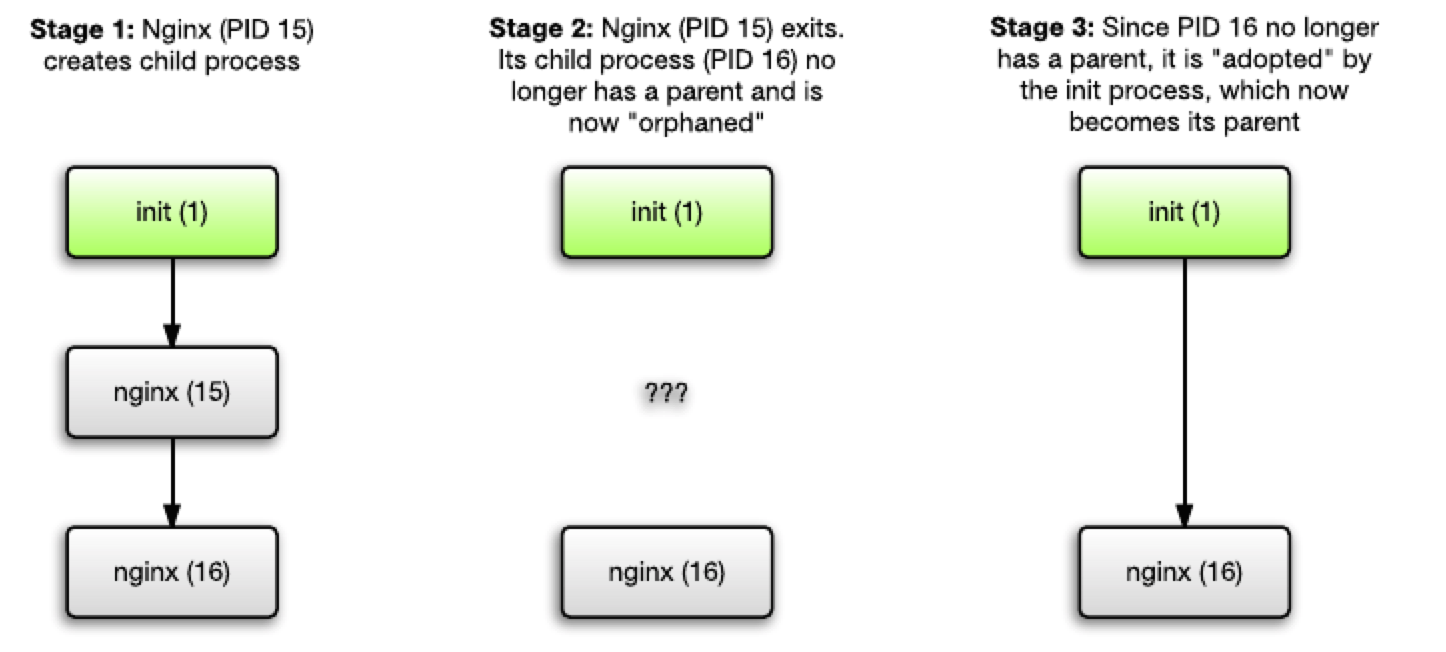
但还有一种特殊情况——如果父进程终止了,无论是正常的(程序逻辑正常终止),还是用户操作导致的(比如用户杀死了该进程)——子进程会如何处理?它们不再拥有父进程,变成了「孤儿进程」(orphaned)(这是确切的技术术语)。
此时初始进程(PID 1)就会因其被赋予地特殊任务而介入——「领养」(adopt)(同样的,这是确切的技术术语)「孤儿进程」。这就意味着初始进程会成为这些子进程的父进程,而无论其是否由初始进程创建。
以 Nginx 为例,其默认就会作为后台程序运行。工作流程如下:Nginx 创建一个子进程后,自身进程结束,然后该子进程就被初始进程「领养」了。
其中的要点是什么?操作系统内核自动处理了「领养」逻辑,因此内核其实是希望初始进程也自动完成对这些「孤儿进程」的“收割”逻辑。
这在 Unix 操作系统中是一个非常重要的机制,大量的软件都是因而设计和实现。几乎所有的服务(daemon)程序都预期初始进程会「领养」和“收割”其守护子进程。
尽管我们是以服务程序做例子,但系统并没有什么机制对此进行规约。任何一个进程在结束时,都会预期初始进程能够清理(「领养」和“收割”)其子进程。这一点,在《操作系统概述》和《Unix 系统高级编程》两书中描述地非常详细。
“僵尸进程”的危害
“僵尸进程”都已经终止了,它们危害在哪里?它们原本占用的内存已经释放了吗?在
ps中除了多了些条目,还有什么别的吗?是的,内存确实已经释放,但能够在
ps中看到,说明它们还仍然占用着一些内核资源。对 Linuxwaitpid的文档引用如下:在“僵尸进程”在被父进程“等待”以彻底消除之前,其仍然会被记录在内核进程表中。而当该表被写满后,新的进程将无法被创建。
对 Docker 的影响
这个问题会如何对 Docker 产生怎样的影响?我们可以看到很多人只在他们的容器中跑一个进程,而且也认为只需要跑这么一个进程就足够了。但显而易见地,这些进程无法承担初始进程在前文中所述的任务逻辑。因此,为了能够正确地“收割”被「领养」的进程,我们需要另外的初始进程来完成这些工作。
举一个相对复杂地例子,我们的容器是一个 web 服务器,需要去跑一段基于 bash 的 CGI 脚本,而该脚本又会去调用 grep 程序。假定 web 服务器发现了 CGI 脚本执行超时,也中止了其继续执行。但此时 grep 程序并不会受到影响仍然继续执行,当其执行结束时,就变成了一个“僵尸进程”并由初始进程(即 web 服务器)「收养」。但 web 服务器无法正确地“收割”这个 grep 进程,所以该“僵尸进程”就在系统中常驻了。
这个问题同样也存在于其它场景中。我们能看到人们尝尝为第三方程序创建 Docker 容器——又如 PostgreSQL ——并将其作为容器中的主进程运行。当我们运行别人的代码时,我们如何确保这些程序并不会派生出子进程并因而堆积大量的“僵尸进程”?唯独仅有我们运行着自己的代码,同时还对所有的依赖包和依赖包的依赖包做严格地审查,才能杜绝这种问题。因此,通常来说,我们很有必要来执行一个合适的初始化系统(init system)来避免这些问题地发生。
解决方案
- 重新编译容器镜像,像baseimage-docker一样,往镜像中引入一套轻量的初始化系统my_init,并将这个
my_init程序作为容器运行的初始进程。 - 将原来的
CMD ["/path-to-your-app"]修改为CMD ["/bin/bash", "-c", "set -e && /path-to-your-app"] && true,这是一个不完善方案,因为没有干净地终止应用进程,可能会造成文件损坏,有风险。
容器的目录被其它的进程使用
现象
在正常停止docker容器后,删除容器报错:
Error response from daemon: Driver devicemapper failed to remove root filesystem a5144c558eabbe647ee9a25072746935e03bb797f4dcaf44c275e0ea4ada463a: remove /var/lib/docker/devicemapper/mnt/25cb26493fd3c804d96e802a95d6c74d7cae68032bf50fc640f40ffe40cc4188: device or resource busy
Error response from daemon: Driver devicemapper failed to remove root filesystem bdd60d5104076351611efb4cdb34c50c9d3f2136fdaea74c9752e2df9fd6f40f: remove /var/lib/docker/devicemapper/mnt/d2b5b784495ece1c9365bdea78b95076f035426356e6654c65ee1db87d8c03e7: device or resource busy
Error response from daemon: Driver devicemapper failed to remove root filesystem 847b5bb74762a7356457cc331d948e5c47335bbd2e0d9d3847361c6f69e9c369: remove /var/lib/docker/devicemapper/mnt/71e7b20dca8fd9e163c3dfe90a3b31577ee202a03cd1bd5620786ebabdc4e52a: device or resource busy
Error response from daemon: Driver devicemapper failed to remove root filesystem a85e44dfa07c060244163e19a545c76fd25282f2474faa205d462712866aac51: remove /var/lib/docker/devicemapper/mnt/8bcd524cc8bfb1b36506bf100090c52d7fbbf48ea00b87a53d69f32e537737b7: device or resource busy
快速解决方案
# 找到使用容器目录的进程
$ find /proc/*/mounts | xargs grep -E "526c823031c2065c6fb3b92f9aaded4477eccceb65f245391a1d8a6acae13d0e"
/proc/27837/mounts:shm /var/lib/docker/containers/526c823031c2065c6fb3b92f9aaded4477eccceb65f245391a1d8a6acae13d0e/shm tmpfs rw,nosuid,nodev,noexec,relatime,size=65536k 0 0
$ ps aux|grep 27837
# 先停掉这些进程后,再就可以成功删除容器了
问题根源
https://github.com/moby/moby/issues/27381
Core of the issue here is that container is either still running or some of its mount points have leaked into other some mount namespace.
You docker-pid and host both seem to be sharing same mount namespace. And that means docker daemon is running in host mount namespace. And that probably means that nginx started at some point after container start and it seems to be running in its own mount namespace. And at that time mount points leaked into nginx mount namespace and that’s preventing deletion of container.
原来是老的内核存在bug,docker进程共享宿主机的mount命名空间,这样容器的挂载点被泄漏给其它进程的命名空间了。
解决方案
升级内核至3.10.0-693.5.2.el7.x86_64以后,另外安装docker仓库里最新的docker-ce:
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce
感想
没想法docker容器化技术发展了这么多年,容器隔离性、基础镜像等这些还存在问题,真是让人想不到,呵呵。
参考
文章作者 Jeremy Xu
上次更新 2018-10-13
许可协议 © Copyright 2020 Jeremy Xu