初识ceph
文章目录
ceph作为新一代的PB级高可靠性分布存储系统已经流行很长时间了,在研究了glusterfs之后,一直想找个机会研究一下它,这周终于抽出来时间了。
概念
相对于其它分布式存储系统,它开创性地用统一的系统提供了对象、块、和文件存储功能,它可靠性高、管理简便、并且是自由软件。Ceph提供了一个可无限伸缩的Ceph存储集群,它基于RADOSA Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters
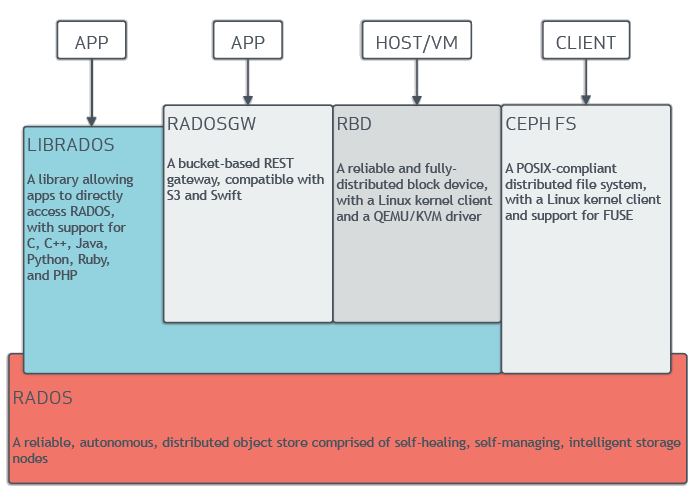
从上面Ceph的架构图可以看到,底层都是RADOS,通过不同的Client(RADOSGW、RBD、CEPHFS)让应用上层识别为一个对象存储系统、块设备、Posix兼容的文件,另外LIBRADOS也使得各种开发语言都可以操作RADOS。
Ceph存储集群包含两种类型的守护进程: Ceph监视器、Ceph OSD守护进程。
Ceph监视器维护着集群运行图的主副本。一个监视器集群确保了当某个监视器失效时的高可用性。存储集群客户端向Ceph监视器索取集群运行图的最新副本。
Ceph OSD守护进程检查自身状态、以及其它OSD的状态,并报告给监视器们。同时Ceph OSD守护进程负责将数据存储为扁平的对象。
Ceph客户端和OSD守护进程都用CRUSH算法来计算对象的位置信息,而不是依赖于一个中心化的查询表。与以往方法相比,CRUSH的数据管理机制更好,它很干脆地把工作分配给集群内的所有客户端和OSD来处理,因此具有极大的伸缩性。CRUSH用智能数据复制确保弹性,更能适应超大规模存储。
Ceph存储系统有存储池的概念,它是存储对象的逻辑分区。每个存储池里都有很多归置组PG(Placement Group),CRUSH算法动态地将PG映射到实际的OSD。
Ceph客户端要进行IO读写操作流程如下:
- Ceph客户端负责把展现给用户的数据格式(一块设备映像、 REST 风格对象、 CephFS 文件系统目录)转换为可存储于 Ceph 存储集群的对象
- Ceph客户端先连接到某个 Ceph 监视器、获得最新的集群运行图副本
- Ceph客户端根据对象的ID及存储池的ID计算得出目标PG的ID
- Ceph客户端得到目标PG的主OSD地址,连接该OSD进行读写操作
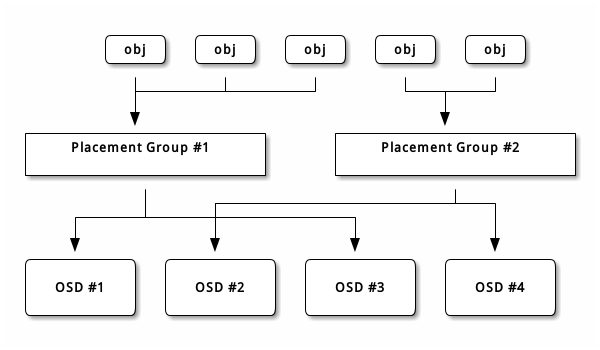
从上面的流程可以看出与glusterfs相比,存储池与OSD之间有PG这么一个中间层。这个中间层使客户端与OSD之间松耦合了,从客户端的角色来看,它只知道对象被存储在某个PG里了,至于对象最终要存储在哪个OSD里它是不感知的。这样当新的OSD上线时,Ceph可以更方便地进行重均衡。
随着OSD数量的增加,一个存储池PG的数量设置将非常重要,它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。官方还提供了一个工具pgcalc。
另外CRUSH算法还支持根据数据存储位置来确定如何存储和检索对象。所以部署一个大规模数据集群的时候,应该好好设计自己的CRUSH图,因为它可以帮助管理 Ceph 集群、提升性能、和保证数据安全性。调整Ceph的CRUSH布局的方法见这里
实操
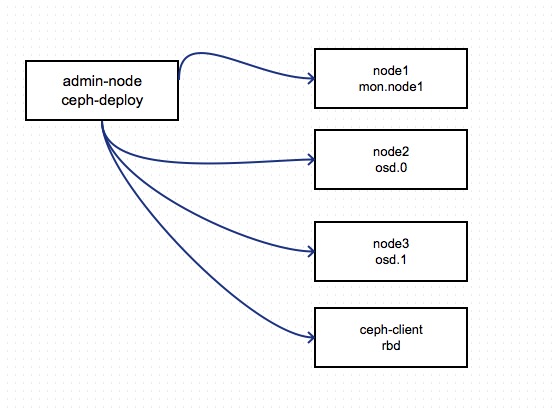
我是在5台CentOS6上进行Ceph在安装的,部署节点的拓扑结构如下:
预检
所有节点更换软件源
#使用阿里云的centos6软件源镜像
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
#使用阿里云的epel软件源镜像
rpm --import http://mirrors.aliyun.com/epel/RPM-GPG-KEY-EPEL-6
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
#使用阿里云的ceph软件源镜像
rpm --import https://download.ceph.com/keys/release.asc
echo "
[ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-el6/hammer/$basearch
enabled=1
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-el6/hammer/noarch
enabled=1
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-el6/hammer/SRPMS
enabled=0
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
" > /etc/yum.repos.d/Ceph.repo
所有节点设置NTP时间同步,可参考之前的`私有云数据中心NTP服务搭建`
所有节点上创建ceph操作用户
```bash
useradd -d /home/cephop -m cephop
passwd cephop
#确保cephop用户有sudo权限
同步hosts文件,确保各节点都可以正确解析节点名称
确保admin-node可无密码SSH登录其它节点
#在admin-node节点执行以下操作
su - cephop
ssh-keygen
ssh-copy-id cephop@node1
ssh-copy-id cephop@node2
ssh-copy-id cephop@node3
ssh-copy-id cephop@ceph-client
echo "
Host node1
Hostname node1
User cephop
Host node2
Hostname node2
User cephop
Host node3
Hostname node3
User cephop
Host ceph-client
Hostname ceph-client
User cephop
" > ~/.ssh/config
禁用ssh的requiretty特性
设置网络接口开机自启动
关闭防火墙
关闭selinux
管理节点安装ceph-deploy
sudo yum install -y ceph-deploy
存储集群安装
mkdir my-cluster
cd my-cluster
ceph-deploy new node1
echo "osd pool default size = 2" >> ceph.conf
ceph-deploy install admin-node node1 node2 node3 ceph-client
ceph-deploy mon create-initial
#在node2, node3上创建上创建osd目录
ssh node2
sudo mkdir /var/local/osd0
exit
ssh node3
sudo mkdir /var/local/osd1
exit
ceph-deploy osd prepare node2:/var/local/osd0 node3:/var/local/osd1
ceph-deploy osd activate node2:/var/local/osd0 node3:/var/local/osd1
ceph-deploy admin admin-node node1 node2 node3
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
ceph health
块设备客户端安装
在管理节点执行下面的命令
ceph-deploy install ceph-client
ceph-deploy admin ceph-client
CentOS6需升级内核才能有brd内核模块,所以在ceph-client上执行下面的命令
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -ivh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel install -y kernel-lt
#修改/boot/grub/menu.lst确保启动后进入新的内核
reboot
#创建块设备映像
rbd create rbd/foo --size 4096
#将块设备映像映射为块设备
sudo rbd map rbd/foo --name client.admin
#格式化块设备
sudo mkfs.ext4 -m0 /dev/rbd1
#后面就可以使用这个块设备了,比如将/dev/rbd1挂载至目录等操作
其它Ceph客户端安装方法类似
总结
- Ceph概念比较多,内部实现细节有很多精彩的地方,使用前务必要把它的体系结构这一章通读一遍。
- Ceph推荐的网络方案是区分了公共网与集群网的,这点比glusterfs进步不少。见这里。
- Ceph里可以自定义CRUSH图,这个比glusterfs只能以地理位置分布进行复制的方案还是灵活不少。
参考
http://docs.ceph.org.cn/architecture/
http://docs.ceph.org.cn/start/
http://blog.dnsbed.com/archives/1714
文章作者 Jeremy Xu
上次更新 2016-08-17
许可协议 © Copyright 2020 Jeremy Xu