初识glusterfs
文章目录
工作中经常发现公司机房里有些服务器上的硬盘空间不足,但还存在一些服务器上有很多空余空间,所以一直在想如何高效利用这些硬盘空间的问题。最初的解决方案是NFS,即在有空余空间的服务器上开启NFS服务器,然后需要硬盘空间的服务器通过NFS挂载过去。用过一段时间后发现存在以下问题:
有空余空间的服务器数量还很多,得作好记录哪个服务器由于什么用途export了哪些目录出去了,export的目录被谁挂载了。
NFS文件共享方式不存在数据冗余存储,主要依靠底层的存储技术如RAID来保证数据的安全。
后来在深度实践KVM这本书里看到了glusterfs,再加上同事也推荐让看一看glusterfs,于是周末花时间研究了下glusterfs,这里作一下记录。
概念
一语句解释glusterfs
GlusterFS is a scalable network filesystem suitable for data-intensive tasks such as cloud storage and media streaming. GlusterFS is free and open source software and can utilize common off-the-shelf hardware.
核心术语
- 集群(Cluster) : 它是相互连接的一组主机,这些主机协同工作共同完成某一个功能,对外界来说就像一台主机一样。
- 可信的存储池(Trusted Storage Pool):它是存储服务器所组成的可信网络。
- 服务器(Server):实际存储数据的服务器。
- 卷(Volume):Brick的逻辑集合。
- 分卷(SubVolume):由多个Brick逻辑构成的卷,它是其它卷的子卷。比如在
分布复制卷中每一组复制的Brick就构成了一个复制的分卷,而这些分卷又组成了分布卷。 - 块(Brick):存储的基本单元,表现为服务器导出的一个目录。
- 客户端(Client):挂载Volume的主机。
卷的种类
- 分布卷(brick count > 1)
- 复制卷(brick count = replica count && replica count > 1)
- 分布复制卷(brick count = replica count * n && replica count > 1 && n > 1)
- 条带卷(stripe count > 1)
- 分布条带卷(brick count = stripe count * n && stripe count > 1 && n > 1)
- 分布条带复制卷(brick count = replica count * stripe count * n && replica count > 1 && stripe count > 1 && n > 1)
- 条带复制卷(brick count = replica count * stripe count && replica count > 1 && stripe count > 1)
- 冗余卷(brick count = disperse count && disperse count > 2 * redundancy count && redundancy count >= 1),这个相当于软件实现的RAID
- 分布冗余卷(brick count = disperse count * n && disperse count > 2 * redundancy count && redundancy count >= 1 && n > 1)
用户空间文件系统工作原理
FUSE用户空间文件系统,原来只是知道,这次终于在glusterfs的官方文档上看到一个较详实的解释了。
Being a userspace filesystem, to interact with kernel VFS, GlusterFS makes use of FUSE (File System in Userspace). For a long time, implementation of a userspace filesystem was considered impossible. FUSE was developed as a solution for this. FUSE is a kernel module that support interaction between kernel VFS and non-privileged user applications and it has an API that can be accessed from userspace. Using this API, any type of filesystem can be written using almost any language you prefer as there are many bindings between FUSE and other languages.
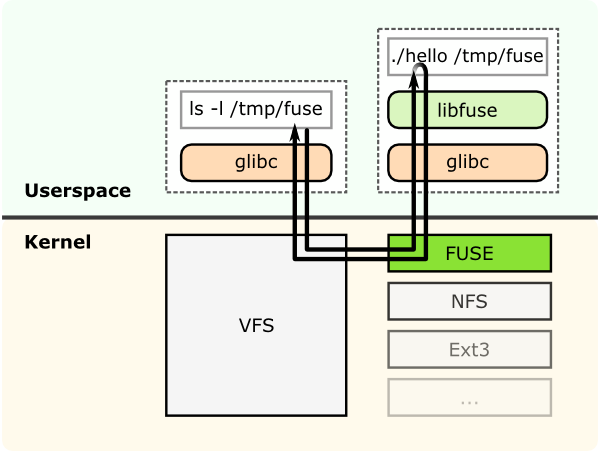
This shows a filesystem “hello world” that is compiled to create a binary “hello”. It is executed with a filesystem mount point /tmp/fuse. Then the user issues a command ls -l on the mount point /tmp/fuse. This command reaches VFS via glibc and since the mount /tmp/fuse corresponds to a FUSE based filesystem, VFS passes it over to FUSE module. The FUSE kernel module contacts the actual filesystem binary “hello” after passing through glibc and FUSE library in userspace(libfuse). The result is returned by the “hello” through the same path and reaches the ls -l command.
The communication between FUSE kernel module and the FUSE library(libfuse) is via a special file descriptor which is obtained by opening /dev/fuse. This file can be opened multiple times, and the obtained file descriptor is passed to the mount syscall, to match up the descriptor with the mounted filesystem.
glusterfs工作原理
下面这段摘自官方文档,我觉得短短几段话,还是描述得挺清楚的。
As soon as GlusterFS is installed in a server node, a gluster management daemon(glusterd) binary will be created. This daemon should be running in all participating nodes in the cluster. After starting glusterd, a trusted server pool(TSP) can be created consisting of all storage server nodes (TSP can contain even a single node). Now bricks which are the basic units of storage can be created as export directories in these servers. Any number of bricks from this TSP can be clubbed together to form a volume.
Once a volume is created, a glusterfsd process starts running in each of the participating brick. Along with this, configuration files known as vol files will be generated inside /var/lib/glusterd/vols/. There will be configuration files corresponding to each brick in the volume. This will contain all the details about that particular brick. Configuration file required by a client process will also be created. Now our filesystem is ready to use. We can mount this volume on a client machine very easily as follows and use it like we use a local storage:
mount.glusterfs <IP or hostname>:<volume_name> <mount_point>
IP or hostname can be that of any node in the trusted server pool in which the required volume is created.
When we mount the volume in the client, the client glusterfs process communicates with the servers’ glusterd process. Server glusterd process sends a configuration file (vol file) containing the list of client translators and another containing the information of each brick in the volume with the help of which the client glusterfs process can now directly communicate with each brick’s glusterfsd process. The setup is now complete and the volume is now ready for client’s service.
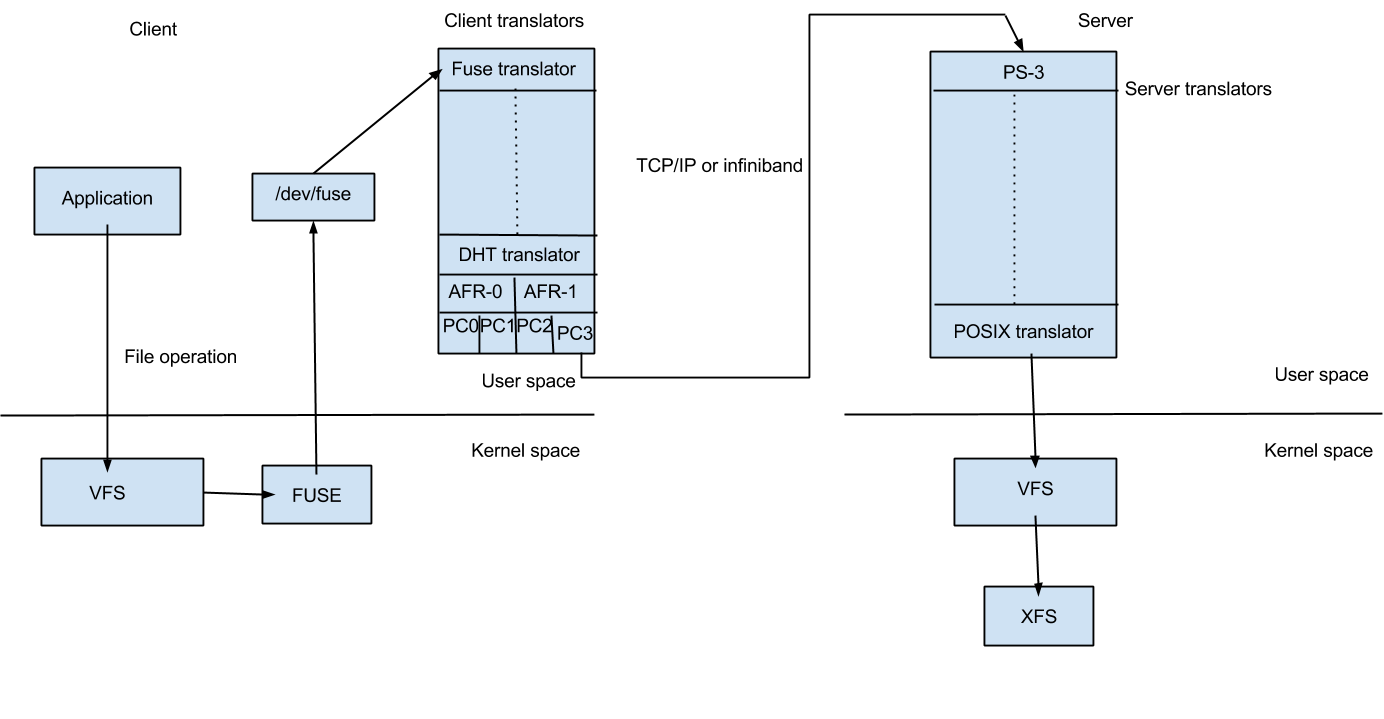
When a system call (File operation or Fop) is issued by client in the mounted filesystem, the VFS (identifying the type of filesystem to be glusterfs) will send the request to the FUSE kernel module. The FUSE kernel module will in turn send it to the GlusterFS in the userspace of the client node via /dev/fuse (this has been described in FUSE section). The GlusterFS process on the client consists of a stack of translators called the client translators which are defined in the configuration file(vol file) send by the storage server glusterd process. The first among these translators being the FUSE translator which consists of the FUSE library(libfuse). Each translator has got functions corresponding to each file operation or fop supported by glusterfs. The request will hit the corresponding function in each of the translators. Main client translators include:
- FUSE translator
- DHT translator- DHT translator maps the request to the correct brick that contains the file or directory required.
- AFR translator- It receives the request from the previous translator and if the volume type is replicate, it duplicates the request and pass it on to the Protocol client translators of the replicas.
- Protocol Client translator- Protocol Client translator is the last in the client translator stack. This translator is divided into multiple threads, one for each brick in the volume. This will directly communicate with the glusterfsd of each brick.
In the storage server node that contains the brick in need, the request again goes through a series of translators known as server translators, main ones being:
- Protocol server translator
- POSIX translator
The request will finally reach VFS and then will communicate with the underlying native filesystem. The response will retrace the same path.
实操glusterfs
准备环境
- 三台CentOS6.8,其中两台作为Server(gfs1, gfs2),一台作为Client(gfs_client)
- 在三台主机上配置好/etc/hosts文件,保证使用名称可解析到正确的ping
- 三台服务器均配置好glusterfs的软件安装源
实操
首先在两台Server执行以下操作
#安装glusterfs的服务器端软件包
yum -y install glusterfs glusterfs-server
#启动glusterfs daemon服务
chkconfig glusterd on
service glusterd start
#配置glusterfs允许外界访问的防火墙规则
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 24007:24008 -j ACCEPT
iptables -A INPUT -p udp -m state --state NEW -m udp --dport 24007:24008 -j ACCEPT
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 49152:49155 -j ACCEPT
iptables -A INPUT -p udp -m state --state NEW -m udp --dport 49152:49155 -j ACCEPT
#保存防火墙配置
service iptables save
service iptables restart
#创建brick存储数据的目录
mkdir -p /data/gfs_b1
然后在gfs1这台Server执行命令
#将gfs2加入到集群节点列表
gluster peer probe gfs2
#查看集群节点状态
gluster peer status
#创建复制卷
gluster volume create gfs_b1 replica 2 gfs1:/data/gfs_b1 gfs2:/data/gfs_b1
#启动卷
gluster volume start gfs_b1
#查看卷状态
gluster volume info && gluster volume status
最后在Client的主机执行以下命令
#安装使用glusterfs的FUSE挂载方式依赖的软件包
yum -y install glusterfs glusterfs-fuse
#创建挂载目录
mkdir -p /mnt/gfs_b1
#写入挂载配置
echo "
gfs1:/gfs_b1 /mnt/gfs_b1 glusterfs defaults,_netdev,transport=tcp 0 0" >> /etc/fstab
#执行挂载
mount -a
除了利用FUSE挂载,也可以使用NFS挂载,可执行以下命令
#在Server端需要添加允许NFS Server供外部访问的防火墙规则
echo "
gfs1:/gfs_b1 /mnt/gfs_b1 nfs defaults,_netdev,mountproto=tcp,vers=3 0 0" >> /etc/fstab
mount -a
常用运维命令
#删除卷
gluster volume stop img
gluster volume delete img
#将机器移出集群
gluster peer detach 172.28.26.102
#只允许172.28.0.0的网络访问glusterfs
gluster volume set img auth.allow 172.28.26.*
#加入新的机器并添加到卷里(由于副本数设置为2,至少要添加2(4、6、8..)台机器)
gluster peer probe 172.28.26.105
gluster peer probe 172.28.26.106
gluster volume add-brick img 172.28.26.105:/data/gluster 172.28.26.106:/data/gluster
#收缩卷,收缩卷前gluster需要先移动数据到其他位置
gluster volume remove-brick img 172.28.26.101:/data/gluster/img 172.28.26.102:/data/gluster/img start
# 查看收缩状态
gluster volume remove-brick img 172.28.26.101:/data/gluster/img 172.28.26.102:/data/gluster/img status
# 收缩完成后提交
gluster volume remove-brick img 172.28.26.101:/data/gluster/img 172.28.26.102:/data/gluster/img commit
# 平衡卷的布局及迁移已有的数据
gluster volume rebalance img start
# 查看平衡状态
gluster volume rebalance img status
# 取消平衡卷的操作
gluster volume rebalance img stop
# 迁移卷 将172.28.26.101的数据迁移到172.28.26.107,先将172.28.26.107加入集群
gluster peer probe 172.28.26.107
gluster volume replace-brick img 172.28.26.101:/data/gluster/img 172.28.26.107:/data/gluster/img start
# 查看迁移状态
gluster volume replace-brick img 172.28.26.101:/data/gluster/img 172.28.26.107:/data/gluster/img status
# 数据迁移完毕后提交
gluster volume replace-brick img 172.28.26.101:/data/gluster/img 172.28.26.107:/data/gluster/img commit
# 如果机器172.28.26.101出现故障已经不能运行,执行强制提交然后要求gluster马上执行一次同步
gluster volume replace-brick img 172.28.26.101:/data/gluster/img 172.28.26.107:/data/gluster/img commit -force
gluster volume heal img full
进一步思考
与常见分布存储相比,优缺点
优点:
- 安装部署简单方便
- 隐藏了元数据的概念,元数据直接以扩展属性的方式存储在文件上
- 兼容POSIX标准,挂载方便
- 与kvm整合较好
- 可作基于地理位置分布的复制,见这里
- 基于LVM,可进行快照管理,见这里
- 可方便地进行配额限制,见这里
- 可方便地进行性能监控,见这里
缺点:
- 用户空间文件系统操作文件的效率相比内核的文件系统可能会慢一些。
- 每一个Brick需要与其它同卷中的Brick建立TCP长连接,为了不至于影响性能,必须限制Brick的数量,好像官方4.x版本正在想办法处理这个问题
- 只提供了基于文件系统的使用方式,不像Ceph那样还提供了对象存储、块设备的使用方式。(可以使用第三方项目SwiftOnFile以支持对象存储)
- 未像Ceph那样隔离管理网络及存储网络,可能会由于管理网络的数据传输拥堵导致存储网络性能降低。(不过我尝试,在服务器上配置双IP,服务器与客户端对主机名作不同的解析可以规避这个问题)
参考
http://gluster.readthedocs.io/en/latest/
文章作者 Jeremy Xu
上次更新 2016-07-25
许可协议 © Copyright 2020 Jeremy Xu