Netty框架研究
文章目录
起因
以前也用Netty做到异步网络编程,用过之后也一直没想过要把Netty拿起来重新研究一翻,直到上周工作中遇到一个棘手的问题。 在我们的项目中基于netty-socketio,我们实现了一个基于WebSocket的浏览器与服务端的请求回应机制。
这里贴一下该机制的大概的代码逻辑,真实项目比这复杂得多。
import com.corundumstudio.socketio.AckRequest;
import com.corundumstudio.socketio.Configuration;
import com.corundumstudio.socketio.SocketConfig;
import com.corundumstudio.socketio.SocketIOClient;
import com.corundumstudio.socketio.annotation.OnConnect;
import com.corundumstudio.socketio.annotation.OnEvent;
import com.corundumstudio.socketio.listener.ConnectListener;
import com.corundumstudio.socketio.listener.DataListener;
import com.corundumstudio.socketio.listener.DisconnectListener;
import io.netty.util.concurrent.Future;
import io.netty.util.concurrent.GenericFutureListener;
import java.util.concurrent.TimeUnit;
/**
* Created by jeremy on 16/6/18.
*/
public class SocketIOServer {
public static void main(String[] args) throws InterruptedException {
SocketIOServer server = new SocketIOServer();
server.start();
TimeUnit.SECONDS.sleep(Long.MAX_VALUE);
}
private void start() {
SocketConfig socketConfig = new SocketConfig();
socketConfig.setReuseAddress(true);
Configuration config = new Configuration();
config.setHostname("0.0.0.0");
config.setPort(8888);
config.setSocketConfig(socketConfig);
config.setContext("/socketio");
com.corundumstudio.socketio.SocketIOServer server = new com.corundumstudio.socketio.SocketIOServer(config);
server.addListeners(new RequestHandler());
server.startAsync().addListener(new GenericFutureListener<Future<? super Void>>() {
public void operationComplete(Future<? super Void> future) throws Exception {
if(future.isSuccess()){
System.out.println("socketio server started.");
}
}
});
}
private class RequestHandler implements ConnectListener, DataListener<String>, DisconnectListener{
public void onConnect(SocketIOClient client) {
System.out.println("client is connected");
}
public void onData(SocketIOClient client, String data, AckRequest ackSender) throws Exception {
System.out.println("receive data");
//这里开始解析请求的数据,然后调用后台Controller层相关接口处理请求,处理完毕之后,向客户端返回响应结果
TimeUnit.SECONDS.sleep(20); //这里用20秒来模拟长时间的耗时操作
client.sendEvent("data", "data response");
}
public void onDisconnect(SocketIOClient client) {
System.out.println("client is disconnected");
}
}
}
最开始功能一切正常,但最近经过压力测试发现,当请求压力上来之后,很多请求在规则的响应时间内都出现超时失败了。
分析原因后发现有问题的关键代码如下
System.out.println("receive data");
//这里开始解析请求的数据,然后调用后台Controller层相关接口处理请求,处理完毕之后,向客户端返回响应结果
TimeUnit.SECONDS.sleep(20); //这里用20秒来模拟长时间的耗时操作
client.sendEvent("data", "data response");
这里实际上是直接使用Netty的NIO线程进行,所以如果业务处理很耗时的话,所以NIO线程都在阻塞等待业务处理完成,这个时候其它请求的IO操作就得不到及时处理。
解决这个问题先
处理这个问题也比较简单,就是将业务的处理放到业务线程池里处理。如下面的代码
private final ExecutorService businessExecutor = Executors.newFixedThreadPool(10);
private class RequestHandler implements ConnectListener, DataListener<String>, DisconnectListener{
public void onConnect(SocketIOClient client) {
System.out.println("client is connected");
}
public void onData(SocketIOClient client, String data, AckRequest ackSender) throws Exception {
businessExecutor.submit(new ProcessRequestTask(client, data));
}
public void onDisconnect(SocketIOClient client) {
System.out.println("client is disconnected");
}
}
private class ProcessRequestTask implements Runnable {
private final String data;
private final SocketIOClient client;
public ProcessRequestTask(SocketIOClient client, String data) {
this.client = client;
this.data = data;
}
public void run() {
try {
System.out.println("receive data");
//这里开始解析请求的数据,然后调用后台Controller层相关接口处理请求,处理完毕之后,向客户端返回响应结果
TimeUnit.SECONDS.sleep(20); //这里用20秒来模拟长时间的耗时操作
client.sendEvent("data", "data response");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
这样Netty的NIO线程就不会由于业务逻辑的处理而阻塞了。
Netty的线程模型
就着这个问题重新复习一下Netty的线程模型
总的来说Netty采用的是Reactor主从多线程模型,工作原理是服务端用于接收客户端连接的是一个独立的NIO线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到IO线程池(sub reactor线程池)的某个IO线程上,由它负责SocketChannel的读写和编解码工作。Acceptor线程池仅仅只用于对接收到的连接作有限的处理,处理完毕后如果链路建立成功,就将链路注册到后端subReactor线程池的IO线程上,由IO线程负责后续的IO操作。
它的线程模型如下图所示:
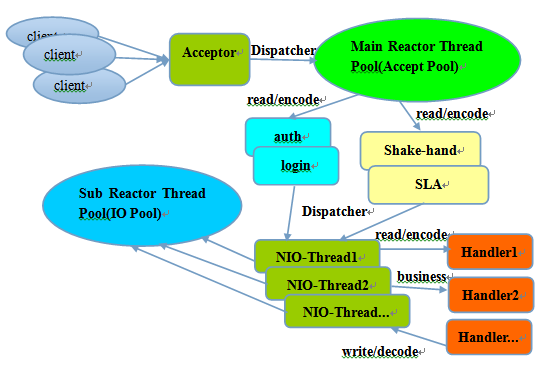
这里结合代码解释一下这里说到的概念
先看一下普通的服务端启动代码
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_REUSEADDR, true)
.childOption(ChannelOption.TCP_NODELAY, true)
.handler(new CheckAcceptHandler())
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast("decoder", new LineBasedFrameDecoder(4096));
ch.pipeline().addLast("stringDecoder", new StringDecoder(StandardCharsets.UTF_8));
ch.pipeline().addLast("lineEncoder", new LineEncoder(StandardCharsets.UTF_8));
ch.pipeline().addLast("logicHandler", new ServerLogicalHandler());
}
});
final int listenPort = 8888;
b.bind(listenPort).sync();
这里bossGroup就是上面说到的负责接收客户端连接的线程池,workGroup就是subReactor线程池,handler(new ChannelInitializer(){...})就是在指定masterReactor线程池里对接收的连接如何处理的逻辑,childHandler(new ChannelInitializer(){...})就是在指定subReactor线程池里对连接后续的IO操作如何处理的逻辑。workGroup的类型是NioEventLoopGroup,而一个NioEventLoopGroup其实是n个NioEventLoop的组合,经过大量经验测算,这个n设置为CPU核心数的两倍整体IO效率较高,所以在Netty里这个n默认就是CPU核心数的两倍。NioEventLoopGroup里NioEventLoop的数目是有限,而Netty本身同时要处理成千上万连接的IO操作。很容易得出结论在Netty里一个NioEventLoop是同时处理多个连接的IO操作的。
一个NioEventLoop聚合了一个多路复用器Selector,因此可以处理成百上千的客户端连接,Netty的处理策略是每当有一个新的客户端接入,则从NioEventLoop线程组中顺序获取一个可用的NioEventLoop,当到达数组上限之后,重新返回到0,通过这种方式,可以基本保证各个NioEventLoop的负载均衡。一个客户端连接只注册到一个NioEventLoop上,这样就避免了多个IO线程去并发操作它。
Netty通过串行化设计理念降低了用户的开发难度,提升了处理性能。利用线程组实现了多个串行化线程水平并行执行,线程之间并没有交集,这样既可以充分利用多核提升并行处理能力,同时避免了线程上下文的切换和并发保护带来的额外性能损耗。
业务操作耗费太多CPU怎么办
Netty本身是通过串行化设计理念来处理万千上万连接的IO操作的。这里就带来一个问题,有一些业务操作就是要耗费太多CPU时间,如何保证处理这样的业务操作时不阻塞Netty的NIO线程?
Netty本身提供了EventExecutorGroup作为业务操作线程池,使用示例如下:
private final EventExecutorGroup businessGroup = new DefaultEventExecutorGroup(4);
private final EventLoopGroup bossGroup = new NioEventLoopGroup();
private final EventLoopGroup workerGroup = new NioEventLoopGroup();
private void start() throws InterruptedException {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_REUSEADDR, true)
.childOption(ChannelOption.TCP_NODELAY, true)
.handler(new CheckAcceptHandler())
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast("decoder", new LineBasedFrameDecoder(4096));
ch.pipeline().addLast("stringDecoder", new StringDecoder(StandardCharsets.UTF_8));
ch.pipeline().addLast("lineEncoder", new LineEncoder(StandardCharsets.UTF_8));
ch.pipeline().addLast(businessGroup, "logicHandler", new ServerLogicalHandler());
}
});
final int listenPort = 8888;
b.bind(listenPort).sync();
}
可以看到ChannelPipeline的add相关方法均提供了一个重载方法,用来指定Handler将在哪个线程池里运行,如果不指定默认就是在Netty的NIO线程池里。
问题又来了,前面说过Netty是采用串行化设计理念处理连接上的IO操作的,这样做可以避免线程竞争,线程上下文切换带来的额外性能损耗。那如果NIO线程与业务线程同时往channel里写数据,这个不是破坏了Netty的串行化理念。刚开始我也这么想,可后来看到Netty底层的write方法才发现并不存在这个问题。
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
这里会判断当前EventExecutor是否是NIO线程,如果是则执行Write操作,否则仅仅是创建一个异步Task,执行该异步Task,该异步Task会到该连接对应的NIO线程里去执行,最终保证还是一个NIO线程串行化地处理该连接上的IO操作。
当然如果不想用EventExecutorGroup,也可以像最上面的示例一样,将长时间的任务丢进自己的业务线程池里处理。
Netty源码研究
花了几天时间结合李林峰的帖子自己翻阅Netty的源码,有了不少收获。Netty框架的源代码解读,李林峰的帖子已经把比较重要写了一遍,这里就不赘述了。这里将我发现的几处亮点记录下来以备忘。
MultithreadEventExecutorGroup是一个多线程的线程池,它提供了一个next方法供外部获取一个EventExecutor来提交Task。而为了MultithreadEventExecutorGroup内部的EventExecutor能比较均衡地干活,每次调用next方法实际上是使用EventExecutorChooser帮助选择一个EventExecutor的,下面是EventExecutorChooser的实现代码
public EventExecutorChooser newChooser(EventExecutor[] executors) {
if (isPowerOfTwo(executors.length)) {
return new PowerOfTowEventExecutorChooser(executors);
} else {
return new GenericEventExecutorChooser(executors);
}
}
private static boolean isPowerOfTwo(int val) {
return (val & -val) == val;
}
private static final class PowerOfTowEventExecutorChooser implements EventExecutorChooser {
private final AtomicInteger idx = new AtomicInteger();
private final EventExecutor[] executors;
PowerOfTowEventExecutorChooser(EventExecutor[] executors) {
this.executors = executors;
}
@Override
public EventExecutor next() {
return executors[idx.getAndIncrement() & executors.length - 1];
}
}
private static final class GenericEventExecutorChooser implements EventExecutorChooser {
private final AtomicInteger idx = new AtomicInteger();
private final EventExecutor[] executors;
GenericEventExecutorChooser(EventExecutor[] executors) {
this.executors = executors;
}
@Override
public EventExecutor next() {
return executors[Math.abs(idx.getAndIncrement() % executors.length)];
}
}
这里针对executors的数目是2的倍数的情况,采用了位操作替换了普通的取模操作。
- Netty内部实现中有很多实例对象内部的状态变更比较频繁,而且这些变更也有可能是由多个线程造成的,为了最小化多线程修改状态所生产的性能开销,同时保证线程安全,采用了大量非阻塞同步的CAS指令实现,这种乐观锁的策略比互斥同步的悲观锁性能高不少。如下面的代码
public abstract class SingleThreadEventExecutor extends AbstractScheduledEventExecutor {
...
private volatile int state = ST_NOT_STARTED;
...
private static final AtomicIntegerFieldUpdater<SingleThreadEventExecutor> STATE_UPDATER;
static{
AtomicIntegerFieldUpdater<SingleThreadEventExecutor> updater =
PlatformDependent.newAtomicIntegerFieldUpdater(SingleThreadEventExecutor.class, "state");
if (updater == null) {
updater = AtomicIntegerFieldUpdater.newUpdater(SingleThreadEventExecutor.class, "state");
}
STATE_UPDATER = updater;
}
...
public boolean isShuttingDown() {
return STATE_UPDATER.get(this) >= ST_SHUTTING_DOWN;
}
...
private void startThread() {
if (STATE_UPDATER.get(this) == ST_NOT_STARTED) {
if (STATE_UPDATER.compareAndSet(this, ST_NOT_STARTED, ST_STARTED)) {
doStartThread();
}
}
}
...
}
NioEventLoop线程除了对多个连接的IO操作进行处理外,本身还需要处理一些定时任务,因而会有以下的代码
protected void run() {
for (;;) {
...
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
processSelectedKeys();
runAllTasks();
} else {
final long ioStartTime = System.nanoTime();
processSelectedKeys();
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
...
}
}
/**
* Poll all tasks from the task queue and run them via {@link Runnable#run()} method. This method stops running
* the tasks in the task queue and returns if it ran longer than {@code timeoutNanos}.
*/
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
if (task == null) {
return false;
}
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
try {
task.run();
} catch (Throwable t) {
logger.warn("A task raised an exception.", t);
}
runTasks ++;
// Check timeout every 64 tasks because nanoTime() is relatively expensive.
// XXX: Hard-coded value - will make it configurable if it is really a problem.
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
this.lastExecutionTime = lastExecutionTime;
return true;
}
run方法里那段代码逻辑很简单,就是处理一些SelectionKey后,按比例抽出一些CPU时间进行队列中任务的处理。runAllTasks方法里从队列里取出任务处理,而且为了在指定的时间内跳出处理任务的逻辑,而且考虑到ScheduledFutureTask.nanoTime()方法比较耗时,每处理64个任务后检查一次,这里为了数字比较高效,又采用了位操作if ((runTasks & 0x3F) == 0)
NioEventLoop的run方法里每次loop都需要处理一些SelectionKey,正常办法是使用selector.selectedKeys()拿到SelectionKey的Set,然后依次处理就好了,但Netty为了高效是拿到SelectionKey的数组进行处理的
...
private SelectedSelectionKeySet selectedKeys;
...
try {
SelectedSelectionKeySet selectedKeySet = new SelectedSelectionKeySet();
Class<?> selectorImplClass =
Class.forName("sun.nio.ch.SelectorImpl", false, PlatformDependent.getSystemClassLoader());
// Ensure the current selector implementation is what we can instrument.
if (!selectorImplClass.isAssignableFrom(selector.getClass())) {
return selector;
}
Field selectedKeysField = selectorImplClass.getDeclaredField("selectedKeys");
Field publicSelectedKeysField = selectorImplClass.getDeclaredField("publicSelectedKeys");
selectedKeysField.setAccessible(true);
publicSelectedKeysField.setAccessible(true);
selectedKeysField.set(selector, selectedKeySet);
publicSelectedKeysField.set(selector, selectedKeySet);
selectedKeys = selectedKeySet;
logger.trace("Instrumented an optimized java.util.Set into: {}", selector);
} catch (Throwable t) {
selectedKeys = null;
logger.trace("Failed to instrument an optimized java.util.Set into: {}", selector, t);
}
private void processSelectedKeys() {
if (selectedKeys != null) {
processSelectedKeysOptimized(selectedKeys.flip());
} else {
processSelectedKeysPlain(selector.selectedKeys());
}
}
package io.netty.channel.nio;
import java.nio.channels.SelectionKey;
import java.util.AbstractSet;
import java.util.Iterator;
final class SelectedSelectionKeySet extends AbstractSet<SelectionKey> {
private SelectionKey[] keysA;
private int keysASize;
private SelectionKey[] keysB;
private int keysBSize;
private boolean isA = true;
SelectedSelectionKeySet() {
keysA = new SelectionKey[1024];
keysB = keysA.clone();
}
@Override
public boolean add(SelectionKey o) {
if (o == null) {
return false;
}
if (isA) {
int size = keysASize;
keysA[size ++] = o;
keysASize = size;
if (size == keysA.length) {
doubleCapacityA();
}
} else {
int size = keysBSize;
keysB[size ++] = o;
keysBSize = size;
if (size == keysB.length) {
doubleCapacityB();
}
}
return true;
}
private void doubleCapacityA() {
SelectionKey[] newKeysA = new SelectionKey[keysA.length << 1];
System.arraycopy(keysA, 0, newKeysA, 0, keysASize);
keysA = newKeysA;
}
private void doubleCapacityB() {
SelectionKey[] newKeysB = new SelectionKey[keysB.length << 1];
System.arraycopy(keysB, 0, newKeysB, 0, keysBSize);
keysB = newKeysB;
}
SelectionKey[] flip() {
if (isA) {
isA = false;
keysA[keysASize] = null;
keysBSize = 0;
return keysA;
} else {
isA = true;
keysB[keysBSize] = null;
keysASize = 0;
return keysB;
}
}
@Override
public int size() {
if (isA) {
return keysASize;
} else {
return keysBSize;
}
}
@Override
public boolean remove(Object o) {
return false;
}
@Override
public boolean contains(Object o) {
return false;
}
@Override
public Iterator<SelectionKey> iterator() {
throw new UnsupportedOperationException();
}
}
看到这里我都惊了,看来Netty团队开发人员连数组与Set两者之间遍历的性能差别都注意到了。
使用Netty进行网络编程注意事项
读了下述的帖子后,发现使用Netty进行网络编程有不少注意事项,这里列举出来以备忘。
- 操作系统的最大句柄数修改
vim /etc/security/limits.conf
* soft nofile 1000000
* hard nofile 1000000
- 尽量不要在Netty的I/O线程上处理业务,业务处理就扔到业务线程池里
- IdleStateHandler,ReadTimeoutHandler,WriteTimeoutHandler处理时延要可控,防止时延不可控导致的NioEventLoop被意外阻塞。
- 合理的心跳周期,具体的心跳周期并没有统一的标准,180S也许是个不错的选择
- 合理设置接收和发送缓冲区容量,用好AdaptiveRecvByteBufAllocator
- 使用Netty的内存池,同时注意完成ByteBuf的解码工作之后必须显式的调用ReferenceCountUtil.release(msg)对接收缓冲区ByteBuf进行内存释放
childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
- NIO线程里尽量异步打日志
- 调整TCP层面的接收和发送缓冲区大小设置,在Netty中分别对应ChannelOption的SO_SNDBUF和SO_RCVBUF,通常建议值为128K或者256K
- 对于时延敏感的应用场景需关闭SO_TCPNODELAY
- Linux内核版本如果大于2.6.35,可考虑开启RPS以实现软中断均衡在多个cpu上,提升网络并行处理性能
- 尽量使用“零拷贝”
- 采用高性能的序列化框架,比如Protobuf、thrift
- 正确地使用互斥同步
- 始终使用wait循环来调用wait方法,永远不要在循环之外调用wait方法。原因是尽管条件并不满足被唤醒条件,但是由于其它线程意外调用notifyAll()方法会导致被阻塞线程意外唤醒,此时执行条件并不满足,它将破坏被锁保护的约定关系,导致约束失效,引起意想不到的结果;
- 唤醒线程,应该使用notify还是notifyAll,当你不知道究竟该调用哪个方法时,保守的做法是调用notifyAll唤醒所有等待的线程。从优化的角度看,如果处于等待的所有线程都在等待同一个条件,而每次只有一个线程可以从这个条件中被唤醒,那么就应该选择调用notify
- 如果一个变量虽然被多线程访问,但只是一个线程写、其它线程读,可考虑只用
volatile关键字来保证线程安全
总结
通过这几天阅读帖子及Netty的源码,对Netty框架的理解深入了许多,现在回头一想以前使用Netty做的网络程序还有不少优化空间。另外这里十分感谢李林峰写的一系列Netty相关的帖子,质量相当高。
参考
http://www.infoq.com/cn/articles/netty-threading-model
http://www.infoq.com/cn/articles/netty-server-create
http://www.infoq.com/cn/articles/netty-concurrent-programming-analysis
http://www.infoq.com/cn/articles/the-multithreading-of-netty-cases
http://www.infoq.com/cn/articles/the-multithreading-of-netty-cases-part02
http://www.infoq.com/cn/articles/netty-elegant-exit-mechanism-and-principles
http://www.infoq.com/cn/articles/netty-high-performance
http://www.infoq.com/cn/articles/netty-million-level-push-service-design-points
文章作者 Jeremy Xu
上次更新 2016-06-18
许可协议 © Copyright 2020 Jeremy Xu